6. As linguagens mais utilizadas

É comum encontrar sistemas no ambiente mainframe onde alguns programas foram escritos em Natural e outros em Cobol; ou parte em Cobol, parte em PL/I e parte em Easytrieve; ou qualquer outra combinação de linguagens de programação diferentes. Isso acontece porque cada linguagem tem vantagens e desvantagens, dependendo da função que o programa pretende executar no sistema. Para o profissional que atua com mainframes é importante ter uma visão geral sobre o que cada uma dessas linguagens pode oferecer.
As linguagens de programação disponíveis no mainframe acompanharam a evolução técnica desses equipamentos ao longo das últimas décadas. Desde a primeira geração de linguagens, com instruções de máquina codificadas em interruptores no painel principal, até as linguagens não procedurais, orientadas a serviços e objetos, todas buscaram (e buscam ainda) aproveitar os recursos introduzidos a cada nova arquitetura de mainframes, sem perder o compromisso com a compatibilidade reversa.
O mainframe conta hoje com linguagens procedurais e não-procedurais, compiladas e interpretadas, linguagens dependentes e linguagens independentes do equipamento. Existem linguagens de finalidade geral, como o Cobol, e linguagens para finalidades específicas, como o RPG, voltado para a geração de relatórios. Hoje os mainframes executam desde programas escritos em Assembler até web services codificados em Java ou C++.
Neste capítulo veremos as linguagens de programação mais utilizadas e que mais facilmente encontramos nas instalações que usam a plataforma mainframe. Não pretendemos neste livro ensinar a programar em nenhuma delas, nem detalhar as regras de sintaxe de cada comando. Queremos apenas que você entenda em que contextos elas são usadas e que saiba identificá-las a partir de um programa fonte.
Todas as linguagens mencionadas aqui usam o próprio TSO como ambiente de desenvolvimento. Com exceção da linguagem Natural, elas não possuem uma IDE específica para construção, compilação e teste. Os programas normalmente são salvos em particionados e compilados em opções do ISPF/PDF ou jobs submetidos para o JES.
JCL
E a primeira linguagem que discutiremos não é exatamente uma linguagem de programação, uma vez que sua estrutura é limitada e não permite a implementação de algoritmos complexos. No entanto, seu uso é importantíssimo no sistema operacional z/OS.
O JCL (Job Control Language) é formado por um conjunto de instruções que basicamente informam ao sistema operacional que programas serão executados em cada job, onde estão os dados de entrada e onde serão gerados os dados de saída. Esta linguagem conta também com algumas estruturas para executar ou não determinados passos (steps) dependendo do resultado dos steps anteriores.
Nesse sentido, ela pode ser comparada aos scripts codificados para o Unix ou aos arquivos de comandos da plataforma Windows. Mas a semelhança termina por aí.
O primeiro contato com o JCL é sempre traumático. Esta é uma linguagem de controle que parece difícil à primeira vista porque possui uma sintaxe extremamente rígida e conta com pouquíssimas opções default. Tudo precisa ser dito ao JCL para que ele faça alguma coisa.
Cartões

Cada linha do job é chamada de “cartão”. Essa convenção vem do tempo em que linhas de jobs e programas eram perfurados em cartões de papelão, um cartão para cada linha. Os cartões que formavam um job ou programa eram empilhados (e mantidos na ordem certa) para que pudessem ser lidos em lote pelo computador.
Todo job começa com um cartão JOB, que é como se fosse um cabeçalho. Ele serve, dentre outras coisas, para que o JES dê um nome para o job e saiba a que “classe” ele pertence. O JES usa essa classe para determinar em que initiators o job pode ser executado.
Um job é formado por diversos steps, e cada um deles possui um cartão EXEC responsável pela execução de um programa ou utilitário.
Cada step pode utilizar um ou mais data sets. Esses data sets são identificados por cartões DD. Cartões DD associam o nome que um programa usa para fazer referência a um arquivo ao nome real que esse arquivo tem (ou terá) no ambiente operacional. Por exemplo, um programa pode ler um arquivo que (internamente) ele chama de ARQENT. Mas esse arquivo na verdade (para o sistema operacional) se chama D1.SISCON.PLANO.CONTAS. O cartão DD é quem faz a associação entre esses dois nomes.
Estrutura do JCL
Todo job deve conter pelo menos um dos seguintes tipos de cartão…
- Um cartão JOB para identificar o job
- Um cartão EXEC, para identificar o programa que será executado
- Um cartão DD, para identificar um data set utilizado pelo programa
No exemplo abaixo temos um job chamado JOB1, que executa um programa chamado AMB0265, que por sua vez vai ler um arquivo chamado YZAAD.SAMA1805:
//JOB1 JOB NOTIFY=ATCL205 //STEP1 EXEC PGM=AMB0265 //DD1 DD DSN=YZAAD.SAMA1805
Naturalmente, um job pode conter (e normalmente contém) vários cartões EXEC (um para cada programa executado) e vários cartões DD (um para cada arquivo acessado). No entanto, apenas um cartão JOB será criado por job.
Os programas são executados na sequência em que aparecem dentro do job. No exemplo abaixo, o programa AMB0200 só será executado depois do programa AMB0210. A ordem em que os cartões DD aparecem, por outro lado, raramente é significativa em cada step.
//JOB1 JOB NOTIFY=ATCL205 //* //STEP1 EXEC PGM=AMB0210 //DD1 DD DSN=YZAAD.SAMA1805,DISP=OLD //DD2 DD DSN=YZAAD.SAMA1806,DISP=NEW //* //STEP2 EXEC PGM=AMB0200 //DD1 DD DSN=YZAAD.SAMA1806,DISP=OLD //DD2 DD DSN=YZAAD.SAMA1807,DISP=NEW
Todas as instalações estabelecem seus próprios padrões de codificação, e com o JCL não é diferente. O padrão de nomenclatura de jobs, steps, programas e arquivos; os valores e as opções obrigatórias em cada comando; os dispositivos de armazenamento que podem ser utilizados… Tudo segue um conjunto de normas definidas pelos administradores do sistema.
Neste livro, utilizaremos um dos inúmeros padrões possíveis. Mas você deve entender que os nomes de jobs, steps, programas e arquivos certamente serão diferentes em cada instalação.
Um exemplo real
Suponha que você precise codificar um job para executar um programa batch bastante simples, escrito em Cobol, chamado XYZP014. Esse programa lê um arquivo sequencial, valida as informações contidas neste arquivo e gera dois arquivos de saída: um com os registros válidos e outro com os registros inválidos.
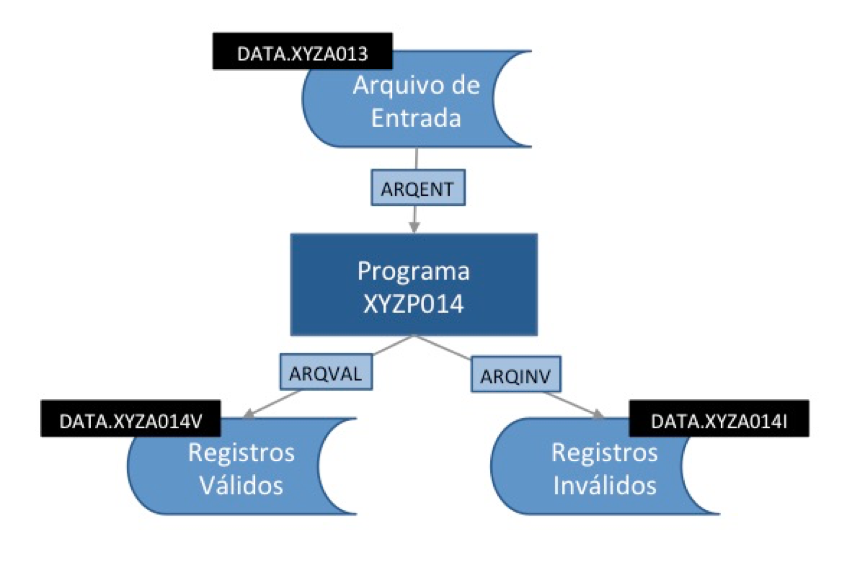
O programa trata internamente o arquivo de entrada com o nome “ARQENT”, e para gerar os arquivos de saída usa também internamente os nomes “ARQVAL” e “ARQINV”.
Externamente, porém, os nomes reais desses arquivos seguirão o padrão de nomenclatura de data sets da empresa: DATA.XYZA013 para o arquivo de entrada, DATA.XYZA014V para o arquivo de registros válidos e DATA.XYZA014I para o arquivo de registros inválidos.
Este job portanto terá apenas um step (a execução do programa) e precisa dizer ao sistema operacional não só quais são os arquivos que o programa pretende acessar, mas também informar todos os parâmetros necessários para a criação dos arquivos de saída.
O job codificado em JCL é mostrado abaixo. A numeração à esquerda de cada linha não existe; ela está aí apenas para facilitar nossas referências mais adiante:
1: //XYZJ014 JOB 'XYZJ0145',CLASS=A,MSGCLASS=X, 2: //*==============================================================* 3: //* VALIDACAO DO ARQUIVO XYZA013 4: //*==============================================================* 5: //STEP001 EXEC PGM=XYZP014 6: //STEPLIB DD DSN=YZAAD.LOADLIB,DISP=SHR 7: //ARQENT DD DSN=DATA.XYZA013,DISP=SHR 8: //ARQVAL DD DSN=DATA-XYZA014V, 9: // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), 10: // DCB=(RECFM=FB,LRECL=62,BLKSIZE=0),UNIT=SYSDA 11: //ARQINV DD DSN=DATA-XYZA014V, 12: // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), 13: // DCB=(RECFM=FB,LRECL=68,BLKSIZE=0),UNIT=SYSDA 14: //SYSOUT DD SYSOUT=* 15: //*
Sem entrar nos detalhes de todas as opções e subopções dos comandos JCL que aparecem neste job, vale chamar a atenção para alguns pontos.
Na primeira linha temos o cartão JOB, que identifica o job para o JES. Neste exemplo, o nome do job é XYZJ014. Esse é o nome que aparecerá nos relatórios gerados pelo JES no final do processamento.
As linhas 2, 3, 4 são comentários. Comentários em JCL sempre são precedidos pelos caracteres //* (barra, barra e asterisco), seguido de alguma informação que será desprezada durante a execução.
A linha 5 mostra o cartão EXEC. Esse é o comando que diz para o sistema operacional que programa será executado. À esquerda da palavra EXEC temos o nome do step (STEP001). Esse nome, com até 8 caracteres, deve ser único dentro do job. Nesta mesma linha temos o parâmetro PGM, seguido do nome do programa que será executado (XYZP014).
A linha 6 contém o primeiro cartão DD do job. O cartão DD associa um ddname (data description name, à esqueda do comando) com um dsname (ou data set name, que aparece à direita). Nesse exemplo, ele está associando o ddname STEPLIB ao dsname YZAAD.LOAD. Para o sistema operacional, isso significa que o programa que pretendemos executar está armazenado no arquivo particionado YZAAD.LOADLIB.
A linha 7 também é um cartão DD. Ele associa o nome que o programa usa para o arquivo de entrada (ARQENT) com o nome real do arquivo no ambiente operacional (DATA.XYZA013). O nome do data set aparece sempre depois da opção DSN=. A opcão DISP=SHR (Disposition Share), no final da linha, informa ao sistema que outros jobs podem ler esse arquivo enquanto o programa estiver sendo executado.
As linhas 8, 9 e 10 identificam outro arquivo usado pelo programa; neste caso, o arquivo de saída que vai receber os registros válidos. É o mesmo cartão DD que mencionamos no parágrafo anterior. Mas por se tratar de um arquivo de saída (que será gerado quando o programa for executado) precisamos informar ao sistema operacional não só seus nomes internos e externos, mas também qual o espaço necessário para armazenar os registros, (parâmetro SPACE), qual o formato dos registros (parâmetro RECFM), o tamanho de cada registro (parâmetro LRECL) e em que unidade de disco pretendemos criá-lo (parâmetro UNIT). A mesma estrutura do cartão DD é usada para declarar o segundo arquivo de saída nas linhas 11, 12 e 13. Esse segundo arquivo vai receber os registros inválidos, gerados pelo nosso programa hipotético.
A linha 14 informa onde serão gravadas as mensagens que eventualmente serão exibidas pelo programa durante a execução. Por exemplo, pode ser que o programa queira exibir a quantidade de registros lidos, a quantidade de registros válidos e quantidade de registros inválidos, no final do processamento. Essas mensagens aparecerão no arquivo (ou no relatório) associados ao ddname SYSOUT. No nosso exemplo, não fornecemos um nome específico para a SYSOUT (ao invés disso, colocamos apenas um asterisco no nome). Para o JES, ,isso significa que todas as mensagens emitidas pelo programa devem ser registradas no relatório default do sistema. Esse será um dos relatórios gerados durante a execução do job, e poderá ser consultado pelo usuário através de ferramentas disponíveis no sistema operacional.
Execução de utilitários e ferramentas
Os steps de um job não executam apenas programas aplicativos, escritos pelo programador. Muitas vezes é necessário inserir alguma função adicional entre um programa e outro.
É comum, por exemplo, um programa gerar um arquivo de saída cujos registros precisam estar numa ordem específica para serem lidos pelo próximo programa. Neste caso, criamos um step entre um programa e outro chamando um utilitário para classificar esse arquivo.
É possível também que em algum momento seja necessário fazer um backup de um arquivo gerado pelo job. Para isso, criamos um step que vai chamar um utilitário que faz cópias de arquivos.
O exemplo abaixo mostra a execução do utilitário de cópia de data sets entre os programas XYZP014 e XYZP015:
//XYZJ014 JOB 'XYZJ0145',CLASS=A,MSGCLASS=X, //*==================================================================* //* VALIDACAO DO ARQUIVO XYZA013 //*==================================================================* //STEP001 EXEC PGM=XYZP014 //STEPLIB DD DSN=YZAAD.LOADLIB,DISP=SHR //ARQENT DD DSN=DATA.XYZA013,DISP=SHR //ARQVAL DD DSN=DATA.XYZA014V, // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), // DCB=(RECFM=FB,LRECL=62,BLKSIZE=0),UNIT=SYSDA //ARQINV DD DSN=DATA.XYZA014I, // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), // DCB=(RECFM=FB,LRECL=68,BLKSIZE=0),UNIT=SYSDA //SYSOUT DD SYSOUT=* //*==================================================================* //* BACKUP DO ARQUIVO DE REGISTROS VALIDOS //*==================================================================* //STEP002 EXEC PGM=IEBGENER //SYSPRINT DD SYSOUT=A //SYSUT1 DD DSN=DATA.XYZA014V,DISP=SHR //SYSUT2 DD DSN=DATA.BACKUP.XYZA014V, // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), // DCB=(RECFM=FB,LRECL=62,BLKSIZE=0),UNIT=SYSDA //SYSIN DD DUMMY //*==================================================================* //* GERACAO DE RELATORIO DE REGISTROS INVALIDOS //*==================================================================* //STEP001 EXEC PGM=XYZP015 //STEPLIB DD DSN=YZAAD.LOADLIB,DISP=SHR //ARQINV DD DSN=DATA.XYZA014I,DISP=SHR //RELINV DD DSN=DATA.REPORT.XYZA014I, // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), // DCB=(RECFM=FB,LRECL=132,BLKSIZE=0),UNIT=SYSDA //SYSOUT DD SYSOUT=*
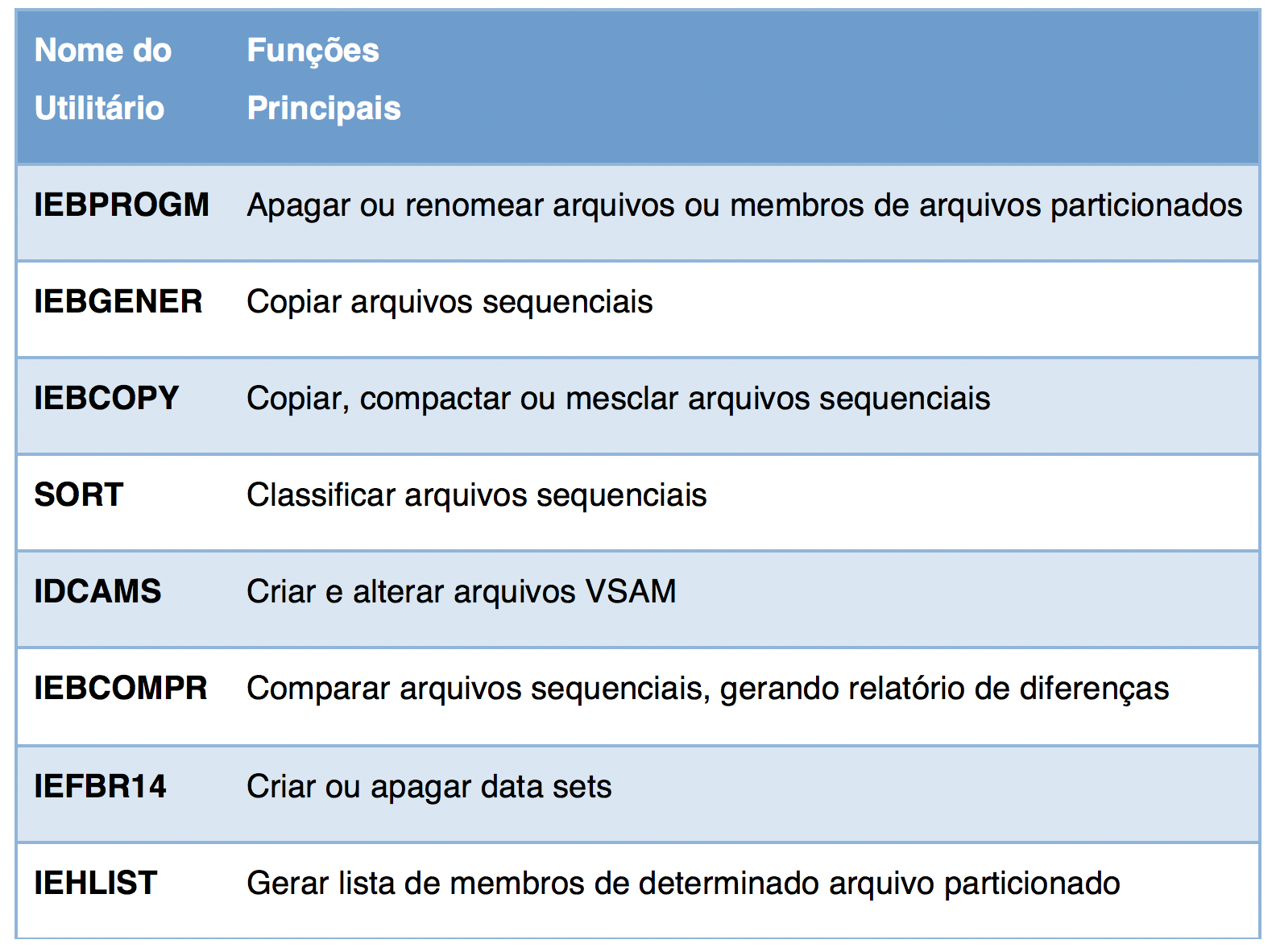
Cada utilitário exige cartões DD e ddnames específicos. Nesse exemplo, estamos chamando o utilitário IEBGENER que tem por finalidade copiar arquivos. O IEBGENER exige que o arquivo de entrada esteja associado ao ddname SYSUT1; o arquivo de saída deve estar associado ao ddname SYSUT2; e as mensagens geradas pelo utilitário devem estar num arquivo associado ao ddname SYSPRINT.
Existem diversos utilitários no sistema operacional z/OS que podem ser chamados pelo JCL. Alguns desses utilitários são:
Execução de jobs
Os jobs normalmente são criados como qualquer outro programa no TSO. Frequentemente são armazenados em particionados juntos com todos os outros jobs de um mesmo sistema.
Para executá-los existem dois métodos principais:
- Editar o arquivo que contém o job e digitar SUB (submit) na linha de comando do editor de textos;
- Utilizar um software gerenciador de produção, como o Control/M.
Os jobs são executados pelo JES, que já vimos em capítulos anteriores. Os resultados da execução ficam em relatórios disponíveis num spool que o usuário pode acessar ao final da execução.
Se o parâmetro NOTIFY for codificado no cartão JOB, o JES enviará uma mensagem para o usuário informando se o job foi executado com sucesso ou não.
A mensagem abaixo, por exemplo, informa que a execução do job foi concluída, e que o “maior condition code” (MAXCC) obtido em todos os steps foi zero, ou seja, nenhum dos steps do job apresentou nenhuma mensagem de erro nem nenhuma advertência.
14.34.34 JOB48406 $HASP165 YZAAW001 ENDED AT ATI1 MAXCC=0 CN(INTERNAL) ***
Um MAXCC diferente de zero indicaria que um dos steps do job apresentou algum problema, ou suspeita de problema. Neste caso, os relatórios disponíveis no spool de execução precisam ser analisados pelo usuário para verificar se era uma condição esperada, ou se algo precisa ser mudado para que o job seja reexecutado.
Se o parâmetros NOTIFY foi codificado no cartão JOB, e esse job contém algum erro de codificação, o JES também envia uma mensagem para o usuário que o submeteu.
14.34.34 JOB48406 $HASP165 YZAAW001 ENDED AT ATI1 - JCL ERROR CN(INTERNAL) ***
Repare que nesse caso a mensagem não mostra o(s) erro(s) de codificação encontrado(s). Caberá ao usuário analisar um dos relatórios gerados no spool de execução, identificar os erros, corrigir e submeter novamente o job para execução.
Algumas regras de sintaxe do JCL
Como já mencionamos, as regras de sintaxe e codificação do JCL são muito rígidas. Quando começamos a trabalhar com JCL temos a sensação de que fizemos tudo certo e o JES simplesmente se recusa a “aprovar” nosso job.
Algumas regras que devem ser respeitadas para que um job esteja sintaticamente correto são:
- Todos os comandos devem começar na coluna 1 com os caracteres // (barra, barra) ou /* (barra, asterisco). Se você incluir um espaço antes do // o JES acusará um erro de codificação.
//XYZJ014 JOB 'XYZJ0145',CLASS=A,MSGCLASS=X,
//*================================================================*
//* VALIDACAO DO ARQUIVO XYZA013
//*================================================================*
//STEP001 EXEC PGM=XYZP014
//STEPLIB DD DSN=YZAAD.LOADLIB,DISP=SHR
//ARQENT DD DSN=DATA.XYZA013,DISP=SHR
//ARQVAL DD DSN=DATA-XYZA014V,
// DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE),
// DCB=(RECFM=FB,LRECL=62,BLKSIZE=0),UNIT=SYSDA
//ARQINV DD DSN=DATA-XYZA014V,
// DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE),
// DCB=(RECFM=FB,LRECL=68,BLKSIZE=0),UNIT=SYSDA
//SYSOUT DD SYSOUT=*
//*
- O jobname, stepname, ou ddname exigidos respectivamente pelos cartões JOB, EXEC e DD, devem ser digitados na coluna 3, logo após os caracteres //. Se houver um espaço entre o // e o nome o JES também acusará um erro de codificação. Depois desses nomes deve haver pelo menos um espaço.
//XYZJ014 JOB 'XYZJ0145',CLASS=A,MSGCLASS=X,
//*================================================================*
//* VALIDACAO DO ARQUIVO XYZA013
//*================================================================*
//STEP001 EXEC PGM=XYZP014
//STEPLIB DD DSN=YZAAD.LOADLIB,DISP=SHR
// ARQENT DD DSN=DATA.XYZA013,DISP=SHR
//ARQVAL DD DSN=DATA-XYZA014V,
// DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE),
// DCB=(RECFM=FB,LRECL=62,BLKSIZE=0),UNIT=SYSDA
//ARQINV DD DSN=DATA-XYZA014V,
// DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE),
// DCB=(RECFM=FB,LRECL=68,BLKSIZE=0),UNIT=SYSDA
//SYSOUT DD SYSOUT=*
//*
- Todos os comandos e parâmetros do JCL devem ser codificados entre as colunas 1 e 71. Se não houver espaço suficiente para todos os parâmetros, ou se o programador quiser separar os parâmetros em várias linhas para melhorar sua legibilidade, deve encerrar uma linha com uma vírgula, escrever os caracteres // nas colunas 1 e 2 da linha seguinte e continuar o comando interrompido.
//XYZJ014 JOB 'XYZJ0145',CLASS=A,MSGCLASS=X, //*================================================================* //* VALIDACAO DO ARQUIVO XYZA013 //*================================================================* //STEP001 EXEC PGM=XYZP014 //STEPLIB DD DSN=YZAAD.LOADLIB,DISP=SHR //ARQENT DD DSN=DATA.XYZA013,DISP=SHR //ARQVAL DD DSN=DATA-XYZA014V, // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), // DCB=(RECFM=FB,LRECL=62,BLKSIZE=0),UNIT=SYSDA //ARQINV DD DSN=DATA-XYZA014V, // DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE), // DCB=(RECFM=FB,LRECL=68,BLKSIZE=0),UNIT=SYSDA //SYSOUT DD SYSOUT=* //*
- Não pode haver espaços entre os parâmetros de um mesmo comando, nem entre as vírgulas que separam os parâmetros:
//XYZJ014 JOB 'XYZJ0145',CLASS=A,MSGCLASS=X,
//*================================================================*
//* VALIDACAO DO ARQUIVO XYZA013
//*================================================================*
//STEP001 EXEC PGM=XYZP014
//STEPLIB DD DSN=YZAAD.LOADLIB,DISP=SHR
//ARQENT DD DSN=DATA.XYZA013,DISP=SHR
//ARQVAL DD DSN=DATA-XYZA014V,
// DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE),
// DCB=(RECFM=FB,LRECL=62,BLKSIZE=0),UNIT= SYSDA
//ARQINV DD DSN=DATA-XYZA014V,
// DISP=(NEW,CATLG,DELETE),SPACE=(TRK,(10,10),RLSE),
// DCB=(RECFM=FB,LRECL=68,BLKSIZE=0),UNIT=SYSDA
//SYSOUT DD SYSOUT=*
//*
Existem muitas outras regras de sintaxe e codificação que parecerão anacrônicas ou irracionais no JCL. Com o tempo, porém, todos se acostumam.
A melhor dica para quem está começando a trabalhar com JCL é: não tente codificar um job do zero. Isso evita uma série de erros bobos, como muitos outros além dos mencionados acima. Na verdade, todos os programadores experientes copiam um job já existente e fazem suas alterações sobre ele. Como, aliás, é o que normalmente fazemos em muitas linguagens de programação.
Cobol
Common Business Oriented Language (COBOL) é certamente a linguagem de programação mais utilizada em mainframes. E também a mais criticada, comentada e controversa. Alguns dos motivos que levam a tanta discussão serão comentados nesta seção.
O COBOL é uma linguagem de programação de alto nível (HLL), de terceira geração (3GL), que adota um modelo de sintaxe semelhante à língua inglesa. Seu alto desempenho no processamento de grandes quantidades de informação fizeram dela a linguagem ideal para processos batch. Ela também é muito usada para a construção de transações on-line, principalmente quando associada ao CICS. Mas existem versões do COBOL que permitem a construção de programas on-line sem necessidade de um gerenciador de transações como o CICS ou o IMS/DC. Essas versões estão disponíveis para construção de programas em ambiente Windows, Mac OS ou Unix.
O COBOL foi desenvolvido por um consórcio chamado CODASYL (Conference on Data Systems Languages), em 1959. Esse consórcio era formado por pesquisadores, empresas e agências do governo americano, e um de seus principais objetivos era definir as regras para uma nova linguagem de programação que permitisse a redução dos custos de construção e manutenção de sistemas do Departamento de Defesa dos Estados Unidos.
O apoio do Departamento de Defesa dos EUA foi determinante para que diversos fabricantes investissem no desenvolvimento de compiladores para essa linguagem. A IBM, por exemplo, anunciou em 1962 que abandonaria seu projeto de desenvolver uma linguagem chamada COMTRAM e adotaria o COBOL como principal linguagem de programação de seus computadores.
Em 1968, para resolver os diversos problemas de compatibilidade entre os compiladores disponíveis, o ISO (International Standard Organization) e o ANSI (American National Standard Institute) se uniram para propor um novo padrão, que incorporasse as melhores soluções de cada fabricante. Desse trabalho surgiu a versão que ficou conhecida como COBOL/68, ou ANS COBOL.
O COBOL vem passando por diversas revisões desde então, incorporando conceitos que surgiram com outras linguagens e recursos possíveis com o desenvolvimento de equipamentos e sistemas operacionais. Cada grande dessas revisões recebe o nome do ano em que foi publicada. Os padrões mais significativos, até o momento, são conhecidos por COBOL/74, COBOL/85, COBOL/2002 e COBOL/2014. Esses dois últimos incorporam o conceito de orientação a objetos, mas podemos afirmar que a maior parte dos programas escritos (ainda hoje) em COBOL adotam o modelo procedimental clássico.
Construção e execução de um programa COBOL
Os programas escritos em COBOL passam por três processos principais antes de serem executados no ambiente mainframe:
Na edição, o programador constrói ou altera o programa fonte usando o editor de texto disponível no ambiente operacional (TSO, ROSCOE, CMS…).

O programa fonte passa então por um processo de compilação, que verificará se as regras de sintaxe e codificação da linguagem foram cumpridas. O compilador normalmente é executado por um job escrito em JCL que foi submetido pelo programador. As mensagens emitidas pelo compilador, inclusive mensagens de erro, são exibidas em relatórios gerados pelo job e disponibilizados no spool de execução após a compilação.

Se nenhum erro impeditivo foi identificado, o compilador gera um programa objeto em linguagem de máquina. Esse programa objeto passa então pelo processo de linkedição, que basicamente estabelece os endereços para as instruções e os dados utilizados pelo programa. Normalmente o linkeditor é executado no mesmo job do compilador (o linkeditor é um step a mais no mesmo job). O linkeditor também gera mensagens para o programador através de relatórios que ficam no spool de execução. Se nenhum problema for detectado, o linkeditor gera um módulo de carga, que na prática é o programa executável.
Uma linha de programa COBOL
Quando o COBOL foi desenvolvido, o principal dispositivo para entrada de dados era a leitora de cartões perfurados. Cada linha de programa fonte era um cartão de papelão perfurado, e o programa em si era uma pilha de cartões.
Por causa disso, até hoje as linhas de um programa Cobol só podem ter 80 caracteres, que era o tamanho máximo do modelo de perfurado mais usado nos anos sessenta. As 80 colunas de uma linha de código Cobol são divididas em cinco áreas, como mostrado na figura 48.

A primeira área, que vai da coluna 1 à coluna 6, é chamada de sequence number area. Ela era originalmente usada para numerar as linhas (ou cartões) de um programa. Programadores e operadores usavam essa coluna para garantir que a pilha de cartões estava na ordem certa. Os editores de programa, hoje, permitem que essa coluna seja numerada, mas isso não é mais exigido pela grande maioria dos compiladores;
A segunda área é chamada de indicator area, e é formada apenas pela coluna 7. Essa coluna pode conter alguns caracteres que fornecem informações específicas para o compilador. Por exemplo, um asterisco (*) nesta coluna indica que a linha é apenas um comentário; um hífen (-) indica que uma sentença ou um literal não coube na linha anterior e continuará nesta linha.
A terceira área é chamada simplesmente de “Área A”, e ocupa as colunas 8 a 11. Algumas estruturas de um programa Cobol (divisões, seções, parágrafos e variáveis de nível 1, especificamente) devem começar obrigatoriamente nesta área.
A quarta área é chamada de “Área B”, e vai da coluna 12 à coluna 72. É usada basicamente para a codificação de variáveis de nível superior a 1 e comandos.
A quinta e última área numa linha Cobol é chamada de identifier area ou program name area e vai da coluna 73 à coluna 80. Quando os programas eram codificados em cartões perfurados, essa área era usada para registrar o nome do programa, que se repetia em todas as linhas ou cartões. Alguns editores de programa numeram essa coluna (por opção do usuário) mas praticamente todos os compiladores ignoram o seu conteúdo.
Compiladores COBOL mais novos usam um formato chamado de “free form”, que não exige essa divisão da linha de codificação em cinco áreas. Mas esses compiladores normalmente rodam em outras plataformas, e não no mainframe.
Estrutura de um programa COBOL
Um programa Cobol é composto por divisões, seções, parágrafos e sentenças.
Todo programa possui quatro divisões, que fornecem um determinado tipo de informação para o compilador e que devem ser codificadas sempre na mesma ordem.

A funcionalidade de um programa é codificada num único componente: o programa fonte. Mas é possível chamar subrotinas que executam uma função específica, reaproveitada por toda a instalação. Cada empresa possui um conjunto de subrotinas padronizadas para finalidades diversas, tais como: validação e operações com data/hora, geração de mensagens padronizadas, formatações especiais para strings e números, tratamento de erros etc.
Subrotinas, na prática, são programas chamados por outros programas. Quando uma subrotina termina, o controle é retornado ao programa chamador. Subrotinas podem ser estáticas ou dinâmicas. Subrotinas estáticas são incorporadas ao programa em tempo de compilação (programa e subrotina passam a fazer parte do mesmo módulo de carga). Subrotinas dinâmicas, por outro lado, são carregadas pelo sistema operacional em tempo de execução do programa principal.
O COBOL permite também que parte do código seja isolado em um componente separado chamado copybook, ou simplesmente book. Esses componentes são inseridos no programa fonte através do comando COPY. Eles permitem, por exemplo, que se codifique a definição dos campos de um arquivo em um book que depois será reutilizado em todos os programas que acessam esse mesmo arquivo. Como no caso das subrotinas, todas as empresas possuem um conjunto de books padronizados que devem ser usados pelos programadores na construção e manutenção de seus programas.
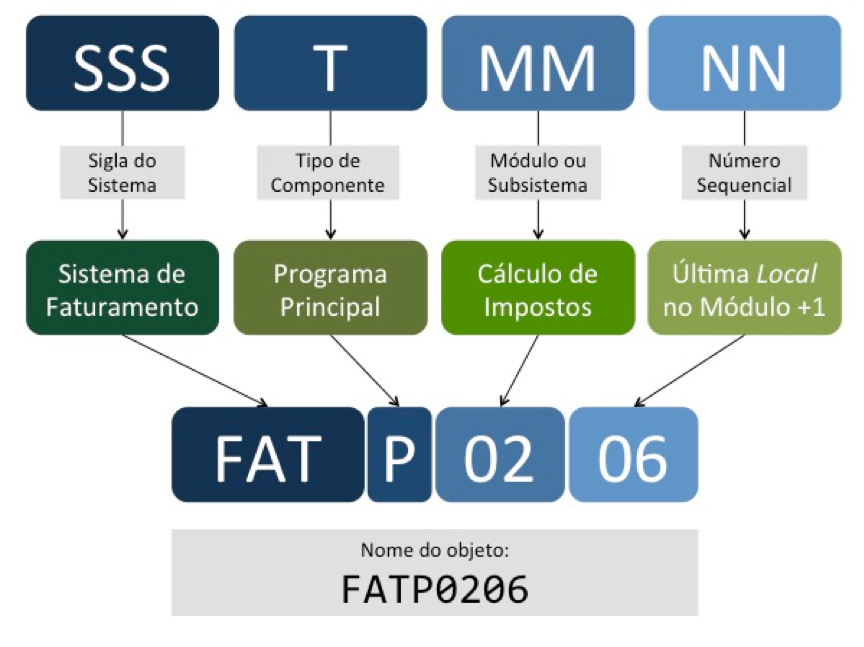
Os nomes de programas, subprogramas e books devem ter no máximo 8 caracteres alfanuméricos, sendo que o primeiro necessariamente deve ser alfabético. É comum que as instalações definam um padrão de nomenclatura que permita ao programador identificar o sistema e o subsistema (ou módulo) ao qual um componente pertence.
O exemplo abaixo é apenas um dos muitos padrões de nomenclatura possíveis, usados pelas empresas:
Exemplo de um programa COBOL
O programa abaixo é um exemplo bem simples de uso do COBOL. Ele deve ler todos os registros de um arquivo de entrada e gravar no arquivo de saída apenas os registros cujo campo nome está preenchido (diferente de espaços).
Observe as informações inseridas na IDENTIFICATION DIVISION, a declaração de arquivos na ENVIRONMENT, as variáveis de trabalho na DATA e os parágrafos e comandos na PROCEDURE.
Observe também as linhas marcadas em verde. Essas são instruções que, juntamente com os nomes das divisões, devem começar na Área A (colunas 8 a 11). As demais linhas necessariamente precisam estar entre as colunas 12 a 72 (Área B).
*================================================================* IDENTIFICATION DIVISION. *================================================================* PROGRAM-ID. TST0101. DATE-WRITTEN. 29/08/2015. INSTALLATION. DATAZ. AUTHOR. JOAO DA SILVA. *REMARKS---------------------------------------------------------* * * * SISTEMA : EXEMPLO PARA TREINAMENTO * * * * PROGRAMA : VALIDAR ARQUIVO * * * * DESCRICAO : VERIFICAR SE O CAMPO NOME DO ARQUIVO DE ENTRA- * * DA ESTA' PREENCHIDO. SO' OS REGISTROS VALIDOS * * SERAO GRAVADOS NO ARQUIVO DE SAIDA * * * * ARQUIVOS E/S DESCRICAO * * -------- --- ----------------------------------------------- * * TSTA0001 E ARQUIVO DE ENTRADA * * TSTA0002 S ARQUIVO DE SAIDA * * * *----------------------------------------------------------------* *================================================================* ENVIRONMENT DIVISION. *================================================================* CONFIGURATION SECTION. SPECIAL-NAMES. DECIMAL-POINT IS COMMA. INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT TSTA0001 ASSIGN TO UT-S-TSTA0001 FILE STATUS IS WS-FILE-STATUS. SELECT TSTA0002 ASSIGN TO UT-S-TSTA0001 FILE STATUS IS WS-FILE-STATUS. *================================================================* DATA DIVISION. *================================================================* FILE SECTION. *---------------------------------------------------------------* * ARQUIVO DE ENTRADA *---------------------------------------------------------------* FD TSTA0001 LABEL RECORD STANDARD RECORDING MODE F RECORD 36. 01 TSTA0001-REGISTRO. 03 TSTA0001-ID PIC 9(006). 03 TSTA0001-NOME PIC X(030). *---------------------------------------------------------------* * ARQUIVO DE SAIDA *---------------------------------------------------------------* FD TSTA0002 LABEL RECORD STANDARD RECORDING MODE F RECORD 36. 01 TSTA0002-REGISTRO. 03 TSTA0002-ID PIC 9(006). 03 TSTA0002-NOME PIC X(030). *----------------------------------------------------------------* WORKING-STORAGE SECTION. *----------------------------------------------------------------* 01 WS-FILE-STATUS PIC X(002) VALUE ZEROS. *================================================================* PROCEDURE DIVISION. *================================================================* 1-INICIO. OPEN INPUT TSTA0001 OPEN OUTPUT TSTA0002. 2-PROCESSO. READ TSTA0001 PERFORM 21-VALIDA-ARQUIVO UNTIL WS-FILE-STATUS NOT = "00". 3-FIM. CLOSE TSTA0001 TSTA0002 STOP RUN. 21-VALIDA-ARQUIVO. IF TSTA0001-NOME NOT = SPACES MOVE TSTA0001-REGISTRO TO TSTA0002-REGISTRO WRITE TSTA0002-REGISTRO END-IF READ ARQUIVO.
O Cobol nas empresas
Diversas pesquisas mostram que o COBOL ainda é a linguagem de programação mais utilizada em sistemas de missão crítica de grandes organizações. Bancos, operadoras de cartão de crédito, empresas de telecomunicação, seguradoras, administradoras de planos de saúde, grandes redes de varejo, entre outras, mantêm seus principais sistemas em COBOL, muitos com milhares de programas e milhões de linhas de código, desenvolvidos anos ou décadas atrás.
Isso pode ser explicado por diversos fatores. Certamente o mais citado é o alto custo envolvido em qualquer tentativa de reescrever esses sistemas para outras plataformas. Mas naturalmente a sobrevivência do COBOL depois de tanto tempo não se deve só a isso.
Há mais de cinquenta anos o COBOL se confirma como uma das linguagens mais estáveis disponíveis no mercado. Cada revisão da linguagem (1974, 1985, 2002…) tem garantido a completa compatibilidade com as versões anteriores, assegurando para as empresas a preservação de anos de investimento. E o mercado já vivenciou experiências decepcionantes em diversas tentativas de migração, ora porque uma nova plataforma não suportou a carga de trabalho suportada pelos mainframes com COBOL, ora porque a evolução das plataformas distribuídas não foi acompanhada por linguagens de programação que entraram e saíram de moda com a mesma rapidez.
Outro fator que justifica a manutenção dessa linguagem, como já mencionamos, é sua altíssima performance no processamento de grandes quantidades de informação, principalmente em rotinas batch. Linguagens como o NATURAL, de quarta geração, nunca apresentaram uma capacidade de processamento semelhante, mesmo em ambiente mainframe.
A grande preocupação dessas empresas hoje em relação ao COBOL é justamente a baixa renovação de profissionais que dominam a linguagem e a forma como algoritmos têm que ser desenhados para aproveitar o melhor dessa tecnologia. As universidades já há algum tempo retiraram o COBOL de seus currículos, e as últimas gerações que se formaram antes disso estão se aposentando. Algumas empresas, cientes do risco da falta de mão-de-obra no futuro próximo, estão investindo em treinamento interno para renovar as equipes responsáveis pelo desenvolvimento e manutenção dos sistemas existentes nessa linguagem.

Críticas e Controvérsias
Talvez existam poucas linguagens de programação tão controversas quanto o COBOL. E essa situação não é recente. O meio acadêmico nunca demonstrou muito interesse pelo desenvolvimento de uma linguagem que pretendia atender a processos comerciais, financeiros e administrativos em geral. O próprio CODASYL foi formado, basicamente, por empresas e agências do governo americano. Nesse distanciamento entre o meio acadêmico e a necessidade das empresas pode estar a origem de diversas críticas que, ainda hoje, ouvimos sobre essa linguagem.
O COBOL foi projetado para tornar os programas auto-documentáveis, fáceis de serem lidos, seguindo uma linguagem semelhante ao inglês.
Não podemos esquecer que, quando essa linguagem surgiu, a ciência da computação dependia predominantemente de linguagens simbólicas, de baixo nível, dominadas por engenheiros que, muitas vezes, haviam trabalhado no projeto dos próprios equipamentos que utilizavam essas linguagens. O COBOL buscou tornar o trabalho de programação mais acessível, mais intuitivo, mais portável e menos dependente das características de cada máquina, uma vez que, perto das linguagens anteriores, seus comandos eram quase autoexplicativos.
Com o passar do tempo, justamente esse modelo sintático foi o causador das primeiras críticas: o COBOL passou a ser considerado “verborrágico”, com suas mais de 300 palavras reservadas e a necessidade de codificação de “frases com verbo e predicado” para realizar operações que as linguagens mais modernas resolvem de forma mais simples.
Outra crítica se deve ao fato de que o COBOL é uma linguagem procedural, num mundo orientado a objetos. É inegável que linguagens como Java ou C++ foram projetadas para facilitar a implementação de abstracões, encapsulamentos, heranças e polimorfismos, conceitos relativamente recentes. O uso dessas linguagens em aplicações interativas é mais do que indicado. Mas o COBOL continua imbatível quando a meta é processar centenas de milhões de registros, em jobs concorrentes, mesmo quando comparado a outras linguagens tradicionais do ambiente mainframe, como NATURAL, Easytrieve ou Rexx.
Também por ser uma linguagem procedural, alguns alegam que é muito fácil escrever um programa de forma ruim. Existem comandos nessa linguagem que são execrados (como o ALTER) ou temidos (como o GO TO) que têm potencial para tornar um programa incompreensível. Mas, convenhamos, é possível codificar mal um programa em qualquer linguagem, e qualquer um que já tenha se confrontado com um sistema orientado a objetos mal projetado sabe disso. O uso do COBOL requer que o programador pense de forma estruturada e domine a arte de desenhar algoritmos.

PL/I
Program Language One (que em português chamamos de “PL um”) é uma linguagem de programação de alto nível, também de terceira geração como o COBOL, desenvolvida pela IBM em meados dos anos 1960 com o objetivo de atender tanto a comunidade científica quanto a comunidade empresarial.
Também como o COBOL, sua sintaxe é semelhante ao inglês, favorecendo a programação estruturada e a forte tipificação de dados. Mas ela incorpora instruções que permitem a construção de programas para cálculos científicos, com funções pré-definidas para cálculo numérico, funções trigonométricas e operações com ponto flutuante.
O processo de compilação do PL/I é igual ao que apresentamos na figura 48. A execução de programas batch via JCL e a interação com o CICS para transações on-line também é similar ao COBOL.
O PL/I não tem o conceito de palavras reservadas: é possível usar qualquer palavra (um comando PL/I, por exemplo) como nome de variável ou bloco. O compilador decide se uma palavra é um comando, uma variável ou um nome de bloco em função do contexto em que a palavra se encontra.
Estrutura de um programa PL/I
Um programa PL/I é formado por blocos do tipo begin-end. Um bloco pode ser formado por declarações de variáveis, comandos, funções e/ou outros blocos. O conceito de blocos no PL/I permite ao programador restringir o escopo de variáveis e arquivos ao bloco onde eles foram declarados. Esse recurso, quando bem utilizado, facilita a construção de programas e sistemas modulares permitindo, por exemplo, esconder os detalhes de implementação de um função a todos os outros componentes do sistema que consomem essa função.
O principal bloco de um programa é chamado de main procedure. Um programa PL/I é executado quando um programa chamador (normalmente o próprio sistema operacional) chama sua main procedure. No exemplo abaixo, IMPRIMIR é a main procedure de um programa que chama outros três programas externos. As linhas em vermelho marcam o início e o fim do bloco principal:
IMPRIMIR:PROCEDURE OPTIONS(MAIN); CALL CABECALHO; CALL DETALHE; CALL RODAPE; END IMPRIMIR;
O programa é encerrado automaticamente depois de executado o último comando da main procedure, e o controle é retornado para o programa chamador. Se ocorrer um erro (abend) durante a execução do programa, o controle também retornará para o programa chamador.
Outras procedures podem ser codificadas no programa, além da procedure principal. Um procedure é uma sequência de declarações e/ou comandos delimitados pela palavra “PROCEDURE” e um “END” correspondente. Uma procedure pode ser uma subrotina ou uma função, e será chamada em algum outro ponto do programa. No exemplo abaixo o programa DTZP0101 obtém um número informado pelo usuário, chama uma função para calcular a raiz quadrada desse número e exibe o resultado. Depois disso o programa é encerrado. As linhas em vermelho destacam o início e o fim de uma procedure, que nesse caso assume o papel de função:
DTZP0101:PROCEDURE OPTIONS(MAIN);
DCL X BIN FLOAT(21) INIT(0);
DCL Y BIN FLOAT(21) INIT(0);
PUT SKIP LIST('INFORME UM NUMERO: ');
GET SKIP EDIT(X);
Y = RAIZ(X);
PUT SKIP LIST ('VALOR CALCULADO: ')
PUT SKIP LIST (Y);
RAIZ: PROCEDURE(U) RETURNS (BIN FLOAT(21));
DCL U BIN FLOAT(21) INIT 0;
DCL V BIN FLOAT(21) INIT 0;
DCL SQRT BUILTIN;
V = SQRT(U);
RETURN(V);
END RAIZ;
END DTZP0101;
O PL/I conta com cerca de 300 funções pré-definidas, também chamadas de built-in functions. No exemplo anterior o programa chama uma dessas funções (SQRT) para calcular a raiz quadrada do número. Existem funções pré-definidas para cálculos numéricos, operações trigonométricas, obter informações sobre dispositivos de I/O, arquivos externos, uso de memória, tratamento de strings etc.
O PL/I nas empresas
Mesmo apresentando algumas vantagens estruturais em relação a COBOL e FORTRAN, o PL/I nunca se tornou, de fato, a “linguagem de programação número 1”, como pretendia a IBM.
Muitas empresas aderiram ao PL/I por conta dos recursos disponíveis e por sua alta capacidade de processamento. Muitos desses sistemas ainda rodam nessas organizações. Os profissionais que dominam essa linguagem são poucos e estão diminuindo. Sua disseminação, porém, nunca foi comparável ao COBOL.
Uma das explicações para isso é que o PL/I surgiu como uma tentativa de atender também à comunidade científica, absorvendo funções do FORTRAN. Mas essa comunidade ao longo do tempo migrou para outras plataformas, linguagens e soluções. Restou ao PL/I competir no mesmo nicho de mercado que o COBOL já dominava com folga.
Apesar disso, desde os anos 1970 têm surgido novos compiladores para programas PL/I, seja para sistemas DOS, Windows, OS/2, AIX, OpenVMS ou Unix.
Exemplo de um programa PL/I
O programa abaixo é um exemplo real de uso do PL/I. Este programa lê um arquivo de entrada para gerar um relatório.
O bloco HEADER_PROC (uma procedure) está inserida na procedure principal (MAIN). Veja como as variáveis são declaradas com o comando declare (DCL) e como duas funções pré-definidas da linguagem (DATETIME e SUBSTR) são declaradas e utilizadas no corpo do programa.
/*********************************************************************/
/* NOME DO PROGRAMA: DTZP010 */
/* DESCRICAO : LE TODOS OS REGISTROS DO ARQUIVO DE ENTRADA */
/* E GERA UM RELATORIO */
/*********************************************************************/
TESTPGM:PROCEDURE OPTIONS(MAIN);
DCL DATETIMEVAR CHAR (17) INIT(' ');
DCL EOUT_LC FIXED DEC (3) INIT (0);
DCL INREC CHAR (80);
DCL MORE_RECORDS BIT (1);
DCL NO BIT (1) INITIAL('0'B);
DCL YES BIT (1) INITIAL('1'B);
DCL 1 PAGENUM FIXED DEC (3) INIT (1);
DCL 1 PAGELN, /* PAGINA */
2 FILLER CHAR (60) INIT (' '),
2 PAGESHOW CHAR (17) INIT ('PAGE : '),
2 PAGEDISP PIC 'ZZ9' INIT (1);
DCL 1 DATELN, /* DATA */
2 FILLER CHAR (60) INIT (' '),
2 DATESHOW CHAR (10) INIT ('RUN DATE: '),
2 DATEDISP CHAR (10) INIT (' / / ');
DCL 1 TIMELN, /* HORA */
2 FILLER CHAR (60) INIT (' '),
2 TIMESHOW CHAR (12) INIT ('RUN TIME: '),
2 TIMEDISP CHAR (08) INIT (' : : ');
DCL 1 PGMSHOW,
2 FILLER1 CHAR (60) INIT (' '),
2 FILLER2 CHAR (20) INIT ('PROGRAMA: DTZP0102');
DCL 1 ENDRPRTLN, /* TRAILLER */
2 FILLER1 CHAR (30) INIT (' '),
2 FILLER2 CHAR (25) INIT ('***** END OF REPORT ****'),
2 FILLER3 CHAR (25) INIT (' ');
DCL BLANKLN CHAR (80) INIT (' ');
DCL 1 HEADERLN,
2 FILLER1 CHAR (20) INIT (' '),
2 FILLER2 CHAR (35) INIT (' LISTA DE 2015'),
2 FILLER3 CHAR (25) INIT (' ');
DCL DATETIME BUILTIN,
SUBSTR BUILTIN;
DCL INP FILE RECORD INPUT,
OUT FILE RECORD OUTPUT;
ON ENDFILE(INP)
MORE_RECORDS = NO;
CLOSE FILE(INP);
ON ENDFILE(OUT)
CLOSE FILE(OUT);
MORE_RECORDS = YES;
OPEN FILE (INP);
OPEN FILE (OUT);
READ FILE (INP) INTO (INREC);
DATETIMEVAR = DATETIME;
PUT SKIP LIST('DATA/HORA',DATETIMEVAR);
SUBSTR(DATEDISP,7,4) = SUBSTR(DATETIMEVAR,1,4);
SUBSTR(DATEDISP,1,2) = SUBSTR(DATETIMEVAR,5,2);
SUBSTR(DATEDISP,4,2) = SUBSTR(DATETIMEVAR,7,2);
SUBSTR(TIMEDISP,1,2) = SUBSTR(DATETIMEVAR,9,2);
SUBSTR(TIMEDISP,4,2) = SUBSTR(DATETIMEVAR,11,2);
SUBSTR(TIMEDISP,7,2) = SUBSTR(DATETIMEVAR,13,2);
CALL HEADER_PROC;
DO WHILE(MORE_RECORDS);
WRITE FILE (OUT) FROM (INREC);
IF EOUT_LC >= 55
THEN DO;
EOUT_LC = 0;
PAGENUM = PAGENUM + 1;
PAGEDISP = PAGENUM;
CALL HEADER_PROC;
END;
EOUT_LC = EOUT_LC + 1;
READ FILE (INP) INTO (INREC);
END;
WRITE FILE (OUT) FROM (BLANKLN);
WRITE FILE (OUT) FROM (ENDRPRTLN);
CLOSE FILE(INP);
CLOSE FILE(OUT);
HEADER_PROC: PROC;
WRITE FILE (OUT) FROM (PAGELN);
WRITE FILE (OUT) FROM (DATELN);
WRITE FILE (OUT) FROM (TIMELN);
WRITE FILE (OUT) FROM (PGMSHOW);
WRITE FILE (OUT) FROM (BLANKLN);
WRITE FILE (OUT) FROM (HEADERLN);
WRITE FILE (OUT) FROM (BLANKLN);
EOUT_LC = EOUT_LC + 7;
END HEADER_PROC;
END TESTPGM;

Natural
O NATURAL é uma linguagem de programação lançada pela empresa alemã Software AG em 1979. É considerada uma linguagem de quarta geração por oferecer um nível de abstração maior que as linguagens da geração anterior. Essas abstrações facilitam, por exemplo, a geração de relatórios e a interação com bancos de dados, que em COBOL e PL/I exigiriam codificação mais detalhada.
Originalmente o NATURAL foi desenvolvido para trabalhar em conjunto com o banco de dados ADABAS. Hoje, porém, essa linguagem funciona perfeitamente com outros SGBDs, como DB2 e Oracle.
O NATURAL possui seu próprio ambiente de desenvolvimento, com editor de programa, construtor de telas e relatórios, manutenção de bibliotecas (sobre as quais falaremos mais adiante) e consulta ao dicionário de dados.

Uma linha de programa na linguagem NATURAL
Os programas fonte em NATURAL são formados por linhas de até 72 colunas. Ao contrário do COBOL, não existem áreas específicas para caracteres de controle ou parâmetros posicionais.
0300* ATUALIZA ULTIMO REGISTRO LIDO 0310* 0320 IF #CONFIRMA = 'S' 0330 UPDATE(150) 0340 END TRANSACTION 0350 END-IF
As linhas são numeradas automaticamente pelo editor de programas. Essa numeração será usada pelo compilador e pelo editor, mas o programador também pode fazer referência ao número de determinada linha dentro do próprio código do programa. O exemplo acima mostra na linha 330 um comando (UPDATE) fazendo referência a uma linha do programa (150). Ele está solicitando que “o registro que foi lido na linha 150 seja atualizado”. Se as linhas forem renumeradas, o editor automaticamente atualiza essas referências.
Estrutura de um programa NATURAL
Um programa em NATURAL é formado por objetos. Tanto o programa quanto seus objetos ficam em bibliotecas mantidas pelo próprio ambiente de desenvolvimento da linguagem. Normalmente os administradores do sistema criam bibliotecas corporativas, onde são centralizados todos os programas e objetos de um sistema. Os programadores também possuem uma biblioteca semelhante para armazenar temporariamente os programas e objetos com os quais estão trabalhando.
O diagrama abaixo mostra a relação de um programa com os diversos tipos de objeto que existem no NATURAL:
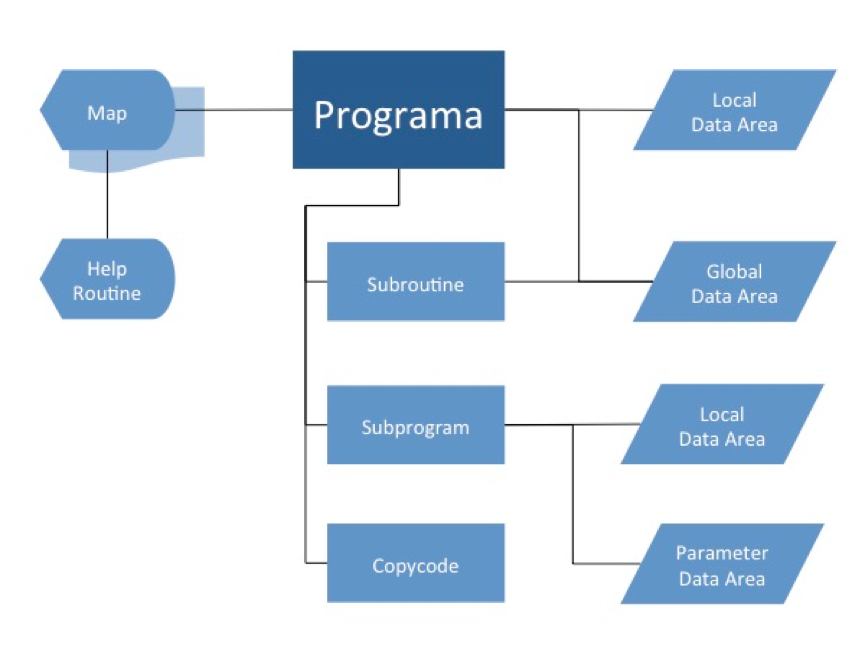
Um copycode contém uma parte de código fonte que será reaproveitada por dois ou mais programas. Ele é inserido no programa através de uma instrução específica (INCLUDE) e será compilado junto com o programa principal.
Global Data Area (também chamado de global) é o objeto onde são definidas variáveis que serão utilizadas por dois ou mais programas. Normalmente os administradores do sistema criam globals corporativas, que devem ser usadas por todos os sistemas da instalação para padronizar a arquitetura das aplicações. A global, suas variáveis e seus valores continuam em memória mesmo após o término da execução do programa.
Local Data Area (ou simplesmente local) também é um objeto para definição de variáveis. Diferentemente da global, a local é eliminada no final da execução do programa.
Parameter Data Area (ou apenas parameter) também é utilizada para definição de variáveis quando essas variáveis e seus valores precisam ser compartilhados entre programas e subprogramas.
Map é o objeto que define uma tela que será usada pelo programa para receber ou exibir dados do/para usuários. No Brasil, normalmente chamamos esse objeto pelo seu nome em português mesmo: mapa. O mapa permite a criação de regras de validação de campos, permitindo que o programa principal se abstraia dessa função. É possível associar cada campo a uma helproutine específica.
Helproutine é o objeto que o programador cria com informações que orientam o usuário no preenchimento de um campo. Pode haver uma helproutine para cada campo de um mapa.
Subprogram é na verdade um programa que é chamado por outro, e que recebe parâmetros através de uma parameter. Quando um subprograma termina, o controle é devolvido ao programa chamador.
Subroutine é um objeto que contém um código que será aproveitado por dois ou mais programas.
Nomenclatura em programas NATURAL
Qualquer objeto, inclusive o programa principal, deve ter um nome de até 8 caracteres alfanuméricos, desde que o primeiro caracter seja alfabético. Variáveis podem ter nomes de até 32 caracteres, e são aceitas letras, números e caracteres especiais como #, -, _, @, $ ou &. Algumas empresas adotam como padrão que as variáveis locais de um programa sempre tenham um nome que comece com #.
Como acontece com o COBOL, cada instalação define um padrão de nomenclatura que permite aos programadores identificar o tipo de objeto, e o sistema, subsistema e/ou módulo aos quais esse objeto pertence. A figura 53 mostra um dos inúmeros padrões de nomenclatura possíveis.

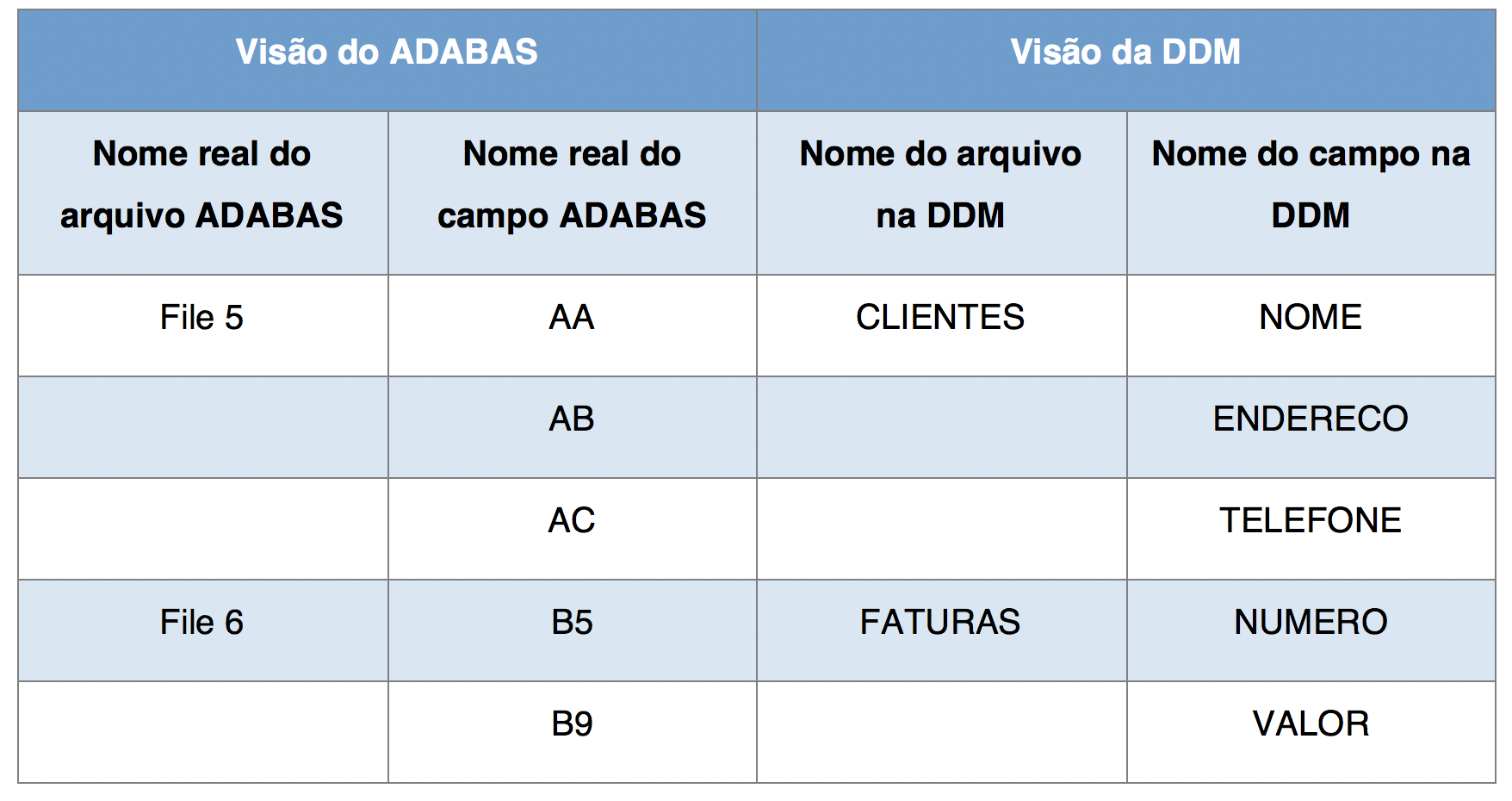
Data Definition Module (DDM)
Um programa NATURAL acessa um arquivo ADABAS através de um componente chamado data definition module, ou DDM. A DDM é uma visão de um arquivo, e toda instalação NATURAL/ADABAS deve ter pelo menos uma DDM para cada arquivo criado no banco ADABAS.
As DDMs contêm nomes, tipos, tamanhos e outros detalhes de todos os campos de determinado arquivo. Ao fazer referência a uma DDM, o programador não precisa criar essas variáveis dentro do programa.
Os arquivos ADABAS são identificados internamente por um número que vai de 1 a 255. Os campos de cada arquivo são identificados por um nome formado por dois caracteres (AA, AB, AC, AD…). As DDMs, no entanto, são identificadas por nomes com até 32 caracteres, e os campos dentro da DDM também podem receber nomes de 3 a 32 caracteres. A associação dos nomes reais do arquivo e de seus campos aos nomes “de fantasia” definidos na DDM é que torna o programa NATURAL mais claro.
Exemplo de programa NATURAL
O programa abaixo é um pequeno programa escrito em NATURAL, que tem por objetivo excluir todos os registros do arquivo CPF-CNPJ-ISENTOS cujo campo SUPERSA seja igual a BAR127.
Repare que o arquivo está declarado na linha 110: à esquerda da palavra reservada VIEW está o nome que o programa usará para se referir ao arquivo (BAR127) e à direita está o nome da DDM que contém os campos desse arquivo (BAR127-01-CPF-CNPJ-ISENTOS-ME).
Da linha 100 à linha 160 existe um bloco demarcado por DEFINE LOCAL DATA / END-DEFINE. Esse bloco define a área de declaração de views e variáveis que serão utilizadas pelo programa.
O algoritmo do programa começa efetivamente na linha 170, após o END-DEFINE. O comando READ faz a leitura e seleção dos registros, e ele mesmo delimita o loop de execução do programa; não há necessidade de estruturas DO WHILE ou DO UNTIL ou similares, apesar da linguagem contar também com esses comandos,
0010 * ****************************************************************** 0020 * SISTEMA..........: CONTROLE DE ARRECADACAO 0030 * PROGRAMA.........: CARP0509 0040 * MODALIDADE.......: BATCH 0060 * OBJETIVO.........: DELETA REGISTROS DA TABELA DE ISENTOS 0070********************************************************************* 0100 DEFINE DATA LOCAL 0110 1 BAR127 VIEW BAR127-01-CPF-CNPJ-ISENTOS-ME 0130 1 #DELETADOS (I04) 0140 1 #CONTROLE (I04) 0160 END-DEFINE 0170 READ BAR127 WITH SUPERSA = 'BAR127' 0180 DELETE 0190 ADD 1 TO #DELETADOS 0200 ADD 1 TO #CONTROLE 0210 IF #CONTROLE >= 100 0220 RESET #CONTROLE 0230 END TRANSACTION 0240 END-IF 0250 * 0260 END-READ 0270 END TRANSACTION 0280 * 0290 WRITE 'QUANTIDADE DE REGISTRO DELATADOS...' #DELETADOS 0300 * 0310 END
O NATURAL nas empresas
O NATURAL teve grande disseminação no Brasil em praticamente todos os órgãos públicos e agências do governo. Também é muito comum em empresas que foram privatizadas nos anos 1990 e 2000.
Essa linguagem pode ser usada para construção de programas batch e on-line. Porém, seu desempenho no processamento batch é bem inferior ao COBOL, ao PL/I e algumas outras linguagens compiladas. A codificação de programas on-line, por outro lado, é muito mais simples no NATURAL do que no COBOL/CICS. Por esse motivo, muitas instalações adotam como padrão o NATURAL para transações on-line e o COBOL para programas batch.
Nos últimos anos o valor das licenças cobradas pela Software AG vem subindo significativamente, o que tem levado diversas empresas a migrar parte de seu portfólio de programas NATURAL/ADABAS para outras linguagens e bancos de dados. Muitos desses projetos de migração estabelecem o COBOL/DB2 como destino.
Easytrieve
Easytrieve é uma linguagem de programação comercializada pela Computer Associates, muito usada em algumas instalações para tratamento de dados e geração de relatórios.
O Easytrieve acessa tanto arquivos convencionais quanto bancos de dados, com comandos que permitem ao programador abstrair detalhes de codificação para execução das tarefas mais usuais. O Easytrieve também permite a chamada a subprogramas escritos em outras linguagens de programação quando for necessário implementar algoritmos mais complexos.
Existem no mercado duas versões principais do Easytrieve: a primeira versão, chamada de Easytrieve Classic, possui uma estrutura mais rígida e limitada. A versão seguinte, batizada de Easytrieve Plus, permitem ao programador construir soluções mais complexas. As duas versões estão disponíveis em diversas empresas. Neste seção abordaremos conceitos e recursos do Easytrieve Plus.
Estrutura de uma linha de programa Easytrieve
Cada linha de um programa Easytrieve contém 80 caracteres. Como no COBOL, o conteúdo das posições 73 a 80 é ignorado pelo compilador, e pode ser usado para numeração das linhas (que alguns editores preenchem automaticamente) ou para identificação de programas.

As linhas de comentário começam com um asterisco. O asterisco não necessariamente precisa estar na coluna 1, mas todos os caracteres anteriores a ele precisam ser brancos.
É possível, mas não recomendado, colocar mais de um comando numa mesma linha, separados por um ponto. Se um comando não couber entre as colunas 1 e 72, é possível indicar a continuação inserindo um + na última posição, como no exemplo abaixo:
TITLE 2 COL 01 'SISTEMA DE ARRECADACAO' COL 40 WDESC-OPCAO +
COL 92 'DATA-HORA EXECUCAO : ' +
COL 113 SYSDATE COL 122 '-' COL 124 SYSTIME
Estrutura de um programa Easytrieve
Um programa Easytrieve é editado, compilado e linkeditado de forma bastante semelhante à que mencionamos sobre a linguagem COBOL. Também são muito semelhantes alguns comandos e tipos de dados usados na definição de variáveis (numérico, numérico compactado, alfanumérico, binário…).
Sua estrutura porém varia de forma significativa. Um programa Easytrieve é formado por três seções, como mostrado na tabela abaixo:
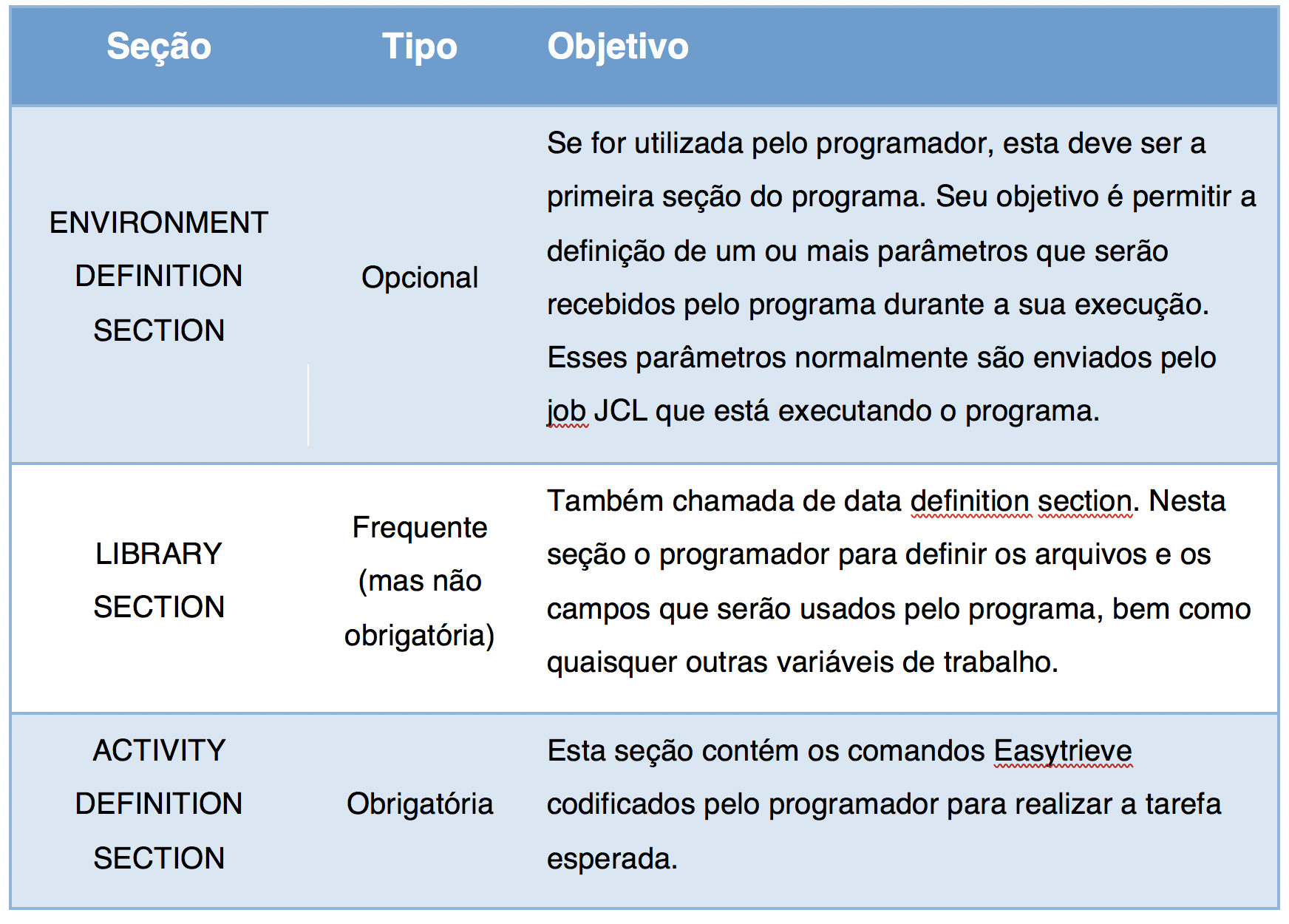
Um programa Easytrieve é formado por uma ou mais atividades. Essas atividades podem ser de dois tipos: SORT e JOB.
Atividades do tipo SORT são aquelas que preparam um arquivo de entrada, colocando seus registros na ordem necessária para a produção de resultados (um relatório, um sumário, o cálculo de um ou mais valores etc).
Atividades do tipo JOB são aquelas que recuperam informações dos arquivos de entrada, e analisam, manipulam, transformam e gravam essas informações em arquivos de saída.
Um programa pode conter qualquer quantidade de atividades SORT e JOB, em qualquer ordem. Cada atividade é composta por comandos, procedures (blocos delimitados por PROC/END-PROC e que podem ser chamadas de diversos pontos do programa) e subatividades.
Os nomes dos programas Easytrieve têm no máximo oito caracteres alfanuméricos, com o primeiro caracter necessariamente alfabético. A prática adotada pelas instalações para padronização desses nomes é semelhante àquelas que mencionamos para as linguagens anteriores.
Exemplo de programa Easytrieve
O código abaixo mostra um programa Easytrieve completo, que tem por objetivo classificar um arquivo de entrada (FILEA) gerando um arquivo temporário (FILEX). O programa então lê esse arquivo temporário e grava no arquivo de saída (FILEB) apenas a primeira ocorrência do campo REF-FAT. Na prática ele está fazendo um “distinct” do arquivo de entrada.
Ele é formado por duas atividades: um SORT (marcado em azul) e um JOB (marcado em vermelho). A atividade JOB chama uma procedure (marcada em verde) toda vez que decide gravar um registro no arquivo de saída.
* ----------------------------------------------------------------- * PROGRAMA = BAREZ939 * OBJETIVO = FORMATA ARQUIVO DE REFERENCIAS DOS REGISTROS NAO * ENCONTRADOS NO FATURADOS/SFA149. *------------------------------------------------------------------ FILE FILEA TIPO-REG 01 06 A REF-FAT 19 06 A * FILE FILEX FB (579 32424) VIRTUAL RETAIN TIPO-REG-X 01 06 A REF-FAT-X 19 06 A * FILE FILEB REF-FAT-B 01 06 A * FILE REL001 PRINTER * LIDOS W 11 N WREF-FAT W 06 A * SORT FILEA TO FILEX USING REF-FAT * JOB INPUT FILEX FINISH GRAVAR-FILEB * IF TIPO-REG-X = 'STATUS;' GO TO JOB END-IF * LIDOS = LIDOS + 1 * IF LIDOS = 1 WREF-FAT = REF-FAT-X END-IF * IF REF-FAT-X NE WREF-FAT PERFORM GRAVAR-FILEB WREF-FAT = REF-FAT-X END-IF * GRAVAR-FILEB. PROC * REF-FAT-B = WREF-FAT PUT FILEB * END-PROC * END
O Easytrieve nas empresas
O grande apelo de marketing do Easytrieve sempre foi a simplicidade para construção de programas destinados a tarefas simples, como por exemplo a formatação de arquivos e a geração de relatórios.
Ele não é usado para procedimentos mais complexos. Algumas empresas, porém, sem uma política mais rigorosa para desenvolvimento de sistemas, permitiram que alguns analistas e programadores usassem essa linguagem “indiscriminadamente”, construindo programas muito complexos, mal documentados e, por isso mesmo, difíceis de manter.
Pegue como o exemplo o programa exemplo que acabamos de mostrar. Este é um programa pequeno, facilmente entendido por qualquer programador que conheça a linguagem. Mas repare que, justamente por conta da simplicidade e abstração da linguagem, faltam comentários e os nomes dos arquivos e variáveis são genéricos. Essa é uma tendência da prática de programação Easytrieve. Agora imagine isso num programa mais complexo, com mil linhas (ou mais), e você terá uma ideia do que queremos dizer quando falamos em “uso indiscriminado”.

| Anterior | Conteúdo | Próxima |