5. Conceitos e Recursos de Software

O profissional que atua na plataforma mainframe convive com um mar de siglas e conceitos relacionados ao software que roda nesse tipo de equipamento. Conhecer algumas características funcionais básicas sobre os sistemas operacionais e as ferramentas mais comuns é essencial para entender como essas máquinas funcionam.
Sistemas operacionais são conjuntos de programas que atuam como intermediários entre usuários e o equipamento físico. Sistemas operacionais não tornam a máquina mais rápida, mas são projetados para garantir que todo o trabalho será realizado pelo computador da forma mais eficiente possível.
Mas o sistema operacional não oferece muitas funcionalidades visíveis para o usuário. Para um mainframe funcionar com toda a sua capacidade é preciso um grande conjunto de produtos, produzidos pela IBM ou por terceiros. E muitos deles estarão presentes em praticamente todas as instalações.
O sistema operacional z/OS
O sistema operacional mais comum em mainframes é o z/OS. Ele é resultado de décadas de pesquisa e evolução de outros sistemas operacionais produzidos pela IBM para as diversas arquiteturas que vêm sendo lançadas desde a década de 1960.
O que chamamos hoje de z/OS já teve vários nomes no passado, e não é raro encontrar profissionais que se referem a ele por seus nomes antigos: OS, MVS ou OS/390.
Os primeiros sistemas operacionais para mainframe só executavam um programa por vez. O sistema processava um job batch solicitado pelo operador e só iniciava o proximo job quando o anterior estivesse concluído. O z/OS evoluiu desse sistema até chegar à capacidade atual de atender milhares de usuários rodando milhares de programas diferentes de forma concorrente.
O z/OS é formado por um conjunto de instruções que controlam as operações de processadores, memória, unidades controladoras e os diversos periféricos que compõem o equipamento, tais como unidades de disco, unidades de fita magnética, canais de comunicação e terminais.
Podemos dizer que o z/OS disponibiliza os serviços básicos que serão consumidos pelos diversos softwares existentes no equipamento. O usuário, especificamente, interage com a máquina quase integralmente através desses softwares, e não diretamente com o sistema operacional.
Quando o z/OS é instalado na máquina pela primeira vez, o que está disponível é:
- Dois protocolos de comunicação para interação com o mundo exterior: SNA e TCP/IP
- Um sistema de gerenciamento de arquivos
- Um sistema operacional UNIX que pode ser usado em máquinas virtuais
- Um ambiente interativo com o qual o usuário pode interagir com a máquina (TSO/E), sobre o qual falaremos mais adiante
- Um sistema para execução de jobs batch (JES)
- Um ambiente de execução de códigos compilados: Runtime Language Environment, ou simplesmente Runtime LE
- Um módulo gerenciador de carga de trabalho (WLM, ou Workload Manager)
- Um módulo para instalação de outros produtos: SMP/E
- Um módulo para identificação e rastreamento de defeitos de hardware e erros de software: EREP
- Um compilador Assembler: HLASM, ou High Level Assembler
- Um servidor HTTP
- E alguns outros utilitários
Parece que é tudo o que a empresa precisa. Mas se prestarmos atenção no que está faltando, perceberemos a importância dos produtos complementares. O que não vem com o sistema operacional é:
- Sistemas gerenciadores de banco de dados
- Sistemas gerenciadores de transação
- Compiladores e linguagens de programação
- Sistemas gerenciadores de segurança e controle de acesso
- Sistemas monitoradores de performance
- Sistemas de impressão
- Sistemas para backup e recuperação de informações
- E alguns outros utilitários importantes
Sobre os produtos que executam essas funções que faltam falaremos mais adiante neste capítulo, juntamente com alguns conceitos e expressões comuns na área de mainframes.

Abend
Um abend (expressão que vem das palavras “abnormal end“) ocorre sempre que o sistema operacional termina uma tarefa ou job de forma anormal. Em outras palavras, alguma coisa deu errado. Esse término anormal pode ocorrer quando hardware, produtos de software ou aplicações detectam alguma tentativa de operação ilegal ou inválida.
Alguns exemplos de “abends” clássicos são:
- Problemas detectados por software: Um job solicita incorretamente um serviço do sistema operacional, de um produto de software ou de um sistema aplicativo.
- Problemas detectados por hardware: Um job tenta acessar um dispositivo de I/O que não está disponível naquela momento, fazendo com que o hardware emita um pedido de interrupção ao sistema operacional.
- Problemas detectados por aplicativo: Uma aplicação “abenda” a si mesma quando detecta uma inconsistência nos dados ou percebe que não produzirá resultados válidos.
O sistema operacional comunica a ocorrência de um abend para o usuário (administrador, operador ou desenvolvedor) através de mensagens geradas na console do operador, no log do sistema ou no log do job.
Essas mensagens nem sempre são claras e intuitivas para o desenvolvedor. Muitas das informações apresentadas estão relacionadas às instruções de baixo nível que estavam sendo executadas pelo processador no momento do abend.
Muitos programadores experientes do ambiente mainframe aprenderam ao longo do tempo a associar um determinado tipo de abend a uma situação específica do programa. Por exemplo, o clássico abend 0C7 normalmente está associado a uma tentativa de operação aritmética com uma variável que não possui conteúdo numérico. O programador, nesse caso, irá procurar as operações aritméticas no programa fonte e muito provavelmente encontrará uma variável cujo valor inicial não foi corretamente atribuído.
Data Sets
Todos os arquivos no z/OS são genericamente chamados de data sets. Antes de gravar qualquer informação em data sets o usuário precisa criá-lo (alocá-lo) manualmente, reservando um espaço em disco para ele e fornecendo algumas outras informações, tais como:
- Data set name: O usuário deve fornecer um nome único para o arquivo Sobre as regras de formação do data set name falaremos mais adiante, neste mesmo tópico.
- Volume Serial: O nome da unidade de disco onde o arquivo será alocado. Normalmente é um nome de seis caracteres definido pelos administradores do sistema e reservado para determinadas finalidades. Os administradores normalmente disponibilizam discos para uso temporário dos programadores, discos para armazenar arquivos de teste, discos para produção (que normalmente não são acessados pelos desenvolvedores) e assim por diante.
- Device Type: O usuário precisa informar também o tipo ou modelo de dispositivo que será usado para armazenar o arquivo, como por exemplo 3380, 3390 ou 9345. Cada modelo de disco tem um tipo de configuração (quantidade de trilhas, quantidade de cilindros e quantidade de setores, com capacidades de espaço diferentes para cada um dessas unidades de medida)
- Organization: O usuário dirá também no momento da criação de que forma esse arquivo será processado: leitura/gravação sequencial, randômica, direta…
- Record format: É o atributo que informa se os registros do arquivo terão um tamanho fixo ou variável.
- Record lenght: O número de caracteres de cada registro no formato fixo, ou o número máximo de caracteres no formato variável.
- Block Size: Se os registros foram agrupados em blocos para economizar espaço, esse atributo especifica o tamanho (em bytes) de cada bloco. Normalmente é um múltiplo do tamanho do registro e cada instalação tem sua própria recomendação para definir o tamanho dos blocos.
- Space ou Primary Extent: Uma quantidade de blocos, trilhas ou cilindros que será reservada no disco para armazenar o arquivo
- Secondary Extent: Um quantidade de blocos, trilhas ou cilindros que será adicionada à capacidade do arquivo quando o primary extent for totalmente ocupado. O z/OS expande o arquivo, quando há necessidade, alocando até 15 secondary extents adicionais. Se um arquivo crescer mais do que isso, será necessário criar manualmente um arquivo com área maior e copiar os dados do arquivo original.
Nesse aspecto, a operação com arquivos no sistema z/OS é bem mais complicada do que em outras plataformas. Um profissional que está começando a trabalhar com mainframes sempre estranha esse “engessamento” do ambiente. Não é possível entrar num editor de texto e fazer um “save as” para um arquivo que não foi previamente criado.
Uma explicação é que esse modelo de arquivo fez parte dos primeiros sistemas operacionais que operavam com discos nos mainframes. E como já discutimos nesse livro, a compatibilidade reversa oferecida pelos mainframes garante que um programa compilado nos anos 1960 continuará funcionando, sem alterações, num equipamento e num sistema operacional lançados no ano passado.
Alguns dos atributos exigidos na criação mostram que no z/OS os arquivos são orientados a registro, enquanto no Windows, no Linux, no MacOS e em outros sistemas operacionais os arquivos são orientados a cadeia de bytes, ou “byte streams“.
Um arquivo do tipo byte stream é basicamente uma sequência de bytes, com um caracter especial para demarcar o fim de um registro e o início de outro. Em arquivos orientados a registro, por outro lado, não há necessidade desse caracter especial porque o tamanho do registro é um dos atributos do arquivo que são definidos pelo usuário no momento em que ele é criado.
O z/OS permite também a criação de arquivos no formato byte stream. Esse padrão é chamado de HFS, mas é mais utilizado em máquinas virtuais que rodam o Linux for System Z.
Criando data sets
O usuário pode alocar, criar, alterar atributos ou excluir data sets através de comandos diretos do TSO, de serviços de acesso disponíveis em utilitários como o VSAM ou através de comandos do JCL. Todos os atributos necessários para a criação dos data sets e mencionados nos parágrafos anteriores podem ser fornecidos qualquer que seja o método usado pelo usuário para a criação do data set.
O nome de um data set, também chamado de dsname, é formado por segmentos, separados por um ponto. Por exemplo, D1.CONTABIL.CONTAS e XPTO.SIST6.FONTES.COBOL são nomes válidos para data sets. O primeiro exemplo possui três segmentos e o segundo exemplo possui quatro. Cada segmento pode ser formado por até oito caracteres, desde que o primeiro caracter seja alfabético ou um caracter especial (#, @ ou $). O nome completo de um data set não pode ultrapassar os 44 caracteres, contando todos os segmentos e os pontos de separação.
Usar muitos qualificadores no nome do data set não é considerado uma boa prática. O nome ZOS.A.B.C.D.E.F.G.H seria válido, mas diz muito pouco sobre o tipo de informação que está armazenado no arquivo.
Normalmente os segmentos buscam mostrar uma hierarquia que facilite o dia a dia de operadores e desenvolvedores. Por exemplo, uma estrutura do tipo XPTO.SIST6.FONTES.COBOL, XPTO.SIST6.FONTES.REXX e XPTO.SIST6.FONTES.JCL podem facilitar o trabalho do usuário, que poderia usar wild cards para procurar todas as bibliotecas de fonte de determinado sistema (por exemplo, XPTO.SIST6.FONTES.*).
O segmento mais à esquerda no nome do data set é conhecido como high-level qualifier, ou HLQ. São os administradores do sistema que estabelecem as regras para definição dos HLQs e o sistema só permitirá que o usuário crie um data set name se seguir padrões de HLQ previamente definidos. Por exemplo, um administrador do sistema pode estabelecer que arquivos usados em desenvolvimento de aplicações devem começar com o segmento DES; arquivo usados em ambiente de produção devem começar com o segmento PRD; e assim por diante.
Apesar de cada instalação poder definir seu próprio conjunto de regras, algumas convenções são praticamente universais:
- As letras LIB em algum segmento sugerem que o data set é uma biblioteca de arquivos. Por exemplo, H0.SISTFAT.COBLIB pode ser um particionado que contém programas escritos em COBOL. Falaremos sobre arquivos particionados no próximo tópico.
- As letras JCL ou JOB em algum segmento indicam que o data set pode conter jobs escritos em JCL. Exemplo: H0.SISTAT.JOBLIB.
- As letras LOAD ou LINK em algum segmento indicam que o data set contém programas executáveis (já compilados e linkeditados). Exemplo: H0.SISTFAT.LOADLIB
- As letras SOURCE ou SOURCE em algum segmento sugerem que o data set contém programas fonte. Exemplo: H0.SISTFAT.SOURCELIB.
Tipos especiais de data sets
Um tipo especial de data set, muito utilizado por programadores, é o partitioned data set, PDS, ou arquivo particionado. Um arquivo particionado é um arquivo (diretório) que contém outros arquivos (membros), e muitas vezes são chamados de libraries ou bibliotecas.
Este tipo de arquivo é muito utilizado, por exemplo, para armazenar programas fonte ou executáveis. Normalmente as instalações possuem várias bibliotecas de programas para cada aplicação, para cada tipo de programa, para cada linguagem de programação etc.
Um membro de um arquivo particionado é acessado colocando-se seu nome ao lado do nome do particionado. Por exemplo, D0.SOURCE.COBOL(SCP0105) faz referência a um programa fonte Cobol chamado SCP0105, que está armazenado no particionado D0.SOURCE.COBOL. Naturalmente, essa dedução vai depender do padrão de nomenclatura que é estabelecido em cada instalação.
Outro tipo relativamente comum é o Generation Data Group (GDG). Esse tipo de data set permite que sejam salvas sucessivas atualizações (ou gerações) de um mesmo arquivo. As diferentes gerações de um GDG são salvas em ordem cronológica. O acesso a cada geração é indicado por um índice (também chamado de nome relativo ou número relativo), que é um inteiro sinalizado que se coloca ao lado do nome do data set.
Assim, por exemplo, o arquivo D1.SISCOB.ARQPLAN(0) representaria a versão mais recente do data set; D1.SISCOB.ARQPLAN(-1) representaria a versão anterior, e assim sucessivamente. Para gerar uma nova versão, usa-se +1 como número relativo.
VSAM
Virtual Storage Access Method, ou VSAM, é um método de alta performance para acesso a arquivos, muito utilizado por aplicações e produtos de software que rodam no sistema operacional z/OS.
Os arquivos acessados pelo VSAM precisam ser criados com uma estrutura específica, formada por dados e índices, que ficam em data sets distintos. O conjunto de data sets que compõem um arquivo do VSAM é chamado de cluster.
O desenvolvedor normalmente cria arquivos VSAM através de um utilitário chamado IDCAMS, executado quase sempre em um job batch.
Control Intervals
Os arquivos VSAM são compostos por unidades de armazenamento chamados de control interval (CI). Todos os CIs do arquivo são do mesmo tamanho, e este tamanho é definido no momento da criação do arquivo: o valor default é 4 KB (valor mínimo), mas pode chegar a 32 KB.
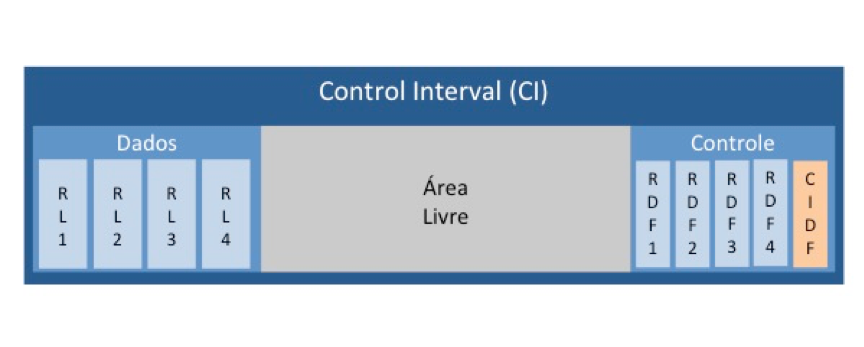
O espaço definido para cada CI será usado para armazenar registros de dados, informações de controle e um espaço livre para inserção de novos registros.
A área de dados é formada pelos registros de dados (também chamados de registros lógicos) que fazem parte do arquivo; essas são as informações efetivamente armazenadas e que são lidas e gravadas pelas aplicações.
A área de controle contém informações sobre cada um dos registros de dados armazenados. Essas informações são chamadas de record definition fields ou RDFs. Existe um RDF para cada registro lógico presente na CI. A área de controle também possui um campo chamado control interval definition field ou CIDF. Há um CIDF para cada CI do arquivo. Sua finalidade é controlar a localização e o tamanho da área livre. A área livre é usada para armazenar mais registros de dados e mais informações de controle.
O conceito de CI é importante porque ele é a unidade de transferência de dados entre o disco e a memória. Logo, seu tamanho tem impacto direto sobre o desempenho do sistema. CIs pequenos podem aumentar consideravelmente a quantidade de operações de I/O de determinado processamento, enquanto CIs grandes podem aumentar a necessidade de memória para armazenar os dados processados.
Normalmente os administradores do sistema definem regras para calcular o tamanho ideal de CI em função da quantidade e do tamanho dos registros de dados que serão armazenados no arquivo.
Control Areas
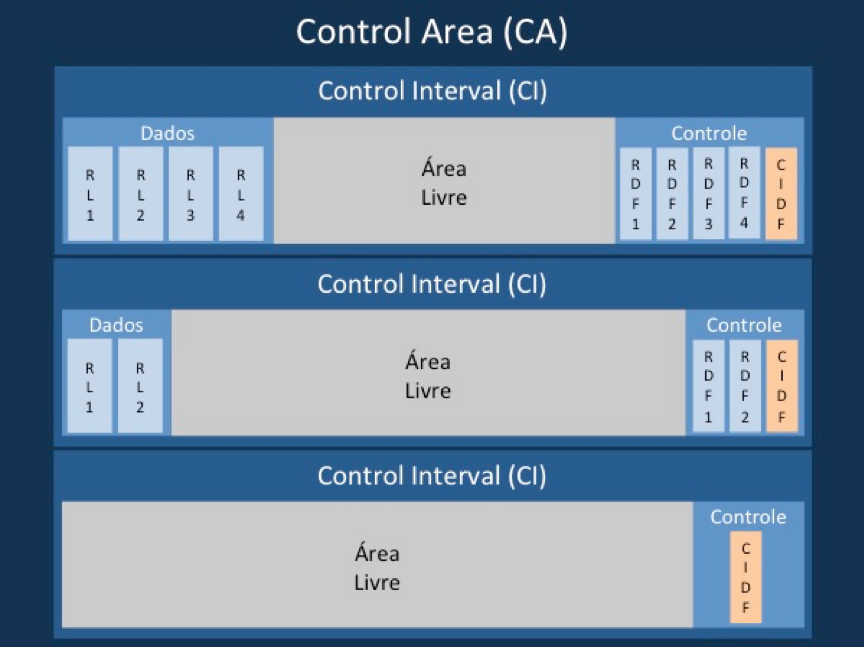
CIs são agrupados em áreas maiores chamadas de control areas ou CAs. A quantidade de CIs por CA é calculada pelo VSAM.
Quando não cabem mais CIs numa CA e não há mais CAs livres, o VSAM expande o arquivo alocando a quantidade cilindros, trilhas ou blocos que foram definidos no parâmetro secondary extent, no momento da criação do arquivo. Como mencionamos no tópico sobre data sets, o z/OS estende arquivos até o limite de 15 extents adicionais.
Tipos de Arquivos VSAM
O VSAM suporta o processamento de três tipos principais de arquivos:
- Nos arquivos do tipo ESDS (Entry-Sequenced Data Set) os registros são armazenados sequencialmente, de acordo com a ordem de entrada. A inclusão de novos registros é realizada sempre no final do arquivo. Esse tipo de arquivo também só pode ser lido sequencialmente, do primeiro ao último registro, na ordem em que foram gravados. Registros não podem ser deletados em arquivos ESDS.
- Nos arquivos do tipo RRDS (Relative Record Data Set), os registros ganham um número relativo quando são gravados. O VSAM permite a leitura e a atualização direta dos registros a partir desse número relativo; programas poderão ler o décimo quarto registro sem ter que passar pelos 13 anteriores, como seria no caso do ESDS. O VSAM permite a deleção de registros em arquivos RRDS: sua posição relativa será marcada como vazia e seu espaço aproveitado em inclusões posteriores.
- Nos arquivos do tipo KSDS (Key Sequenced Data Set) cada registro possui uma ou mais chaves de acesso. Essas chaves normalmente fazem parte do registro (um campo “número de matrícula” num registro de alunos, por exemplo) e são usadas tanto pelos programas para acessar determinados registros quanto pelo VSAM para estabelecer a ordem de armazenamento. A VSAM permite a atualização e/ou exclusão de registros a partir do valor das chaves.
Os arquivos ESDS e RRDS são pouco utilizados em sistemas aplicativos que utilizam o VSAM. Arquivos KSDS, por outro lado, são muito comuns e muitas vezes são chamados apenas de “arquivos indexados”.
O VSAM exige a definição de pelo menos uma chave para arquivos KSDS. Essa chave é chamada de chave primária e seus valores devem identificar unicamente cada registro dentro do arquivo (não pode haver dois registros de alunos com o mesmo valor no campo “matrícula”, por exemplo). O VSAM permite também a criação de chaves secundárias, que podem ser únicas ou não.
Splits
O split é uma operação que o VSAM executa para resolver problemas de espaço em arquivos KSDS. Quando a ocorrência de splits é muito grande em determinado arquivo, os sistemas que utilizam esse arquivo sofrem degradação de performance. Por esse motivo precisam ser minimizados por desenvolvedores e administradores de sistemas. É importante então que a gente entenda como o split funciona e por que ele acontece.
O VSAM tenta manter as chaves primárias em ordem dentro de cada CI, e cria um CI especial (chamado CI de índice) para associar o valor da chave com o CI onde o registro está armazenado. O VSAM armazena no CI de Índice o maior valor de chave presente em cada CI de dados.
A figura 30 mostra a relação entre o CI de Índice e três CIs de Dados. O primeiro CI de Dados está totalmente preenchido, o segundo possui área livre e o terceiro está totalmente vazio.
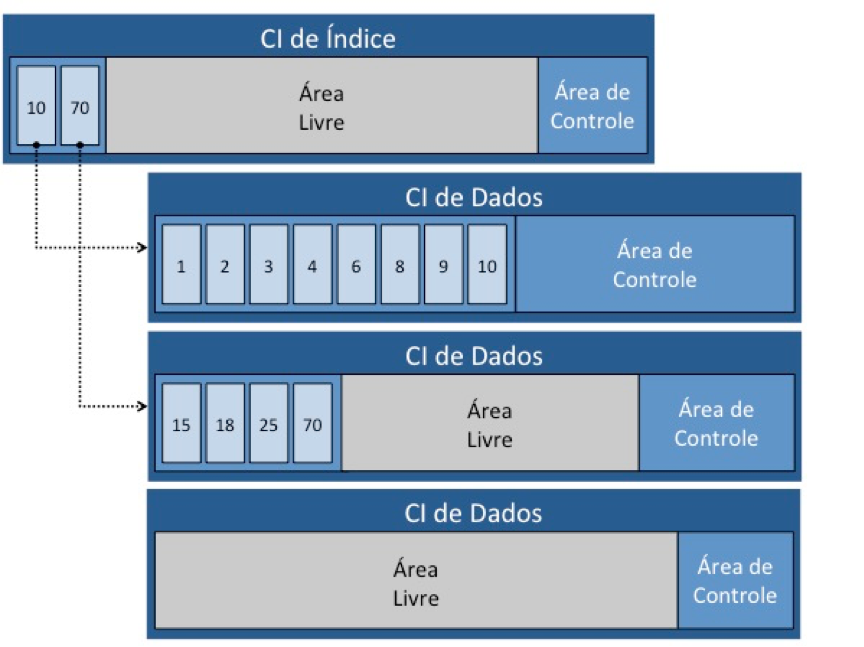
No CI de índice existem dois registros, com valores 10 e 70. Eles representam os maiores valores das chaves primárias dos registros que estão armazenados em cada CI de Dados.
Imagine agora que queremos inserir neste arquivo um registro com valor de chave igual a 5. O VSAM, como dissemos, tenta manter os registros em ordem dentro de cada CI para ganhar agilidade no acesso. Ele vai tentar inserir o registro 5 no primeiro CI, mantendo-o entre os registros 4 e 6. Como não há espaço ele terá que separar (ou splitar) ou primeiro CI, passando o registro 10 para o CI de baixo e assim liberar espaço.
Suponha agora que o segundo CI também estivesse totalmente ocupado. Nesse caso o VSAM teria que passar o registro 70 para o terceiro CI, passar o registro 10 para o segundo e, só então, inserir o registro 5.
Para complicar mais um pouco, poderia acontecer de todo o CA dos três CIs estivesse ocupado. Nesse caso haveria não só uma série de splits de CI, mas também um split de CA, com alguns registros passando de CI em CI, CIs passando de um CA para o outro e assim sucessivamente… tudo no momento em que o programa solicitasse a inclusão de um registro no arquivo.
Uma forma de evitar isso é definindo um valor ideal para o parâmetro FREESPACE, no momento em que o arquivo VSAM é criado. Esse parâmetro estabelece qual o espaço vazio que deve permanecer em cada CI quando o arquivo for carregado pela primeira vez. Isso garantiria que nas operações do dia a dia haveria em todos os CIs algum espaço disponível para acomodar mais registros.
No entanto, não se deve simplesmente atribuir um valor muito grande para o FREESPACE, pois quanto mais espaço disponível exigirmos do VSAM, menos registros caberão em cada CI. Com isso, menos registros serão transferidos do disco para a memória a cada leitura. E isso também poderia afetar a performance.
O uso de arquivos VSAM oferece uma série de vantagens para o desenvolvedor e para os sistemas que os utilizam. Sua performance é significativamente melhor do que outros métodos de acesso, como os proporcionados por SGBDs, por exemplo.
No entanto, cada KSDS VSAM deve ser analisado e planejado individualmente antes de ser criado. Nessa análise, deve-se estimar a quantidade média de registros que o arquivo terá, a quantidade de inserções, atualizações e exclusões ao longo do tempo, o tamanho dos registros e das chaves, o tamanho dos CIs, o tamanho do FREESPACE e assim por diante.
TSO
O Time Sharing Option/Extension (TSO/E) é o programa que permite ao usuário interagir com o z/OS, seja ele administrador do sistema, operador ou desenvolvedor. Através do TSO os usuários podem entrar no z/OS, executar programas e criar, modificar e eliminar data sets.
O Interactive System Productivity Facility (ISPF) e seu componente Program Development Facility (ISPF/PDF) trabalham juntos com o TSO/E disponibilizando telas e menus com as quais o usuário pode interagir. O ISPF é uma ferramenta que permite a criação de telas e seqüências de navegação. O PDF é uma estrutura criada em ISPF para ajudar usuários a manter arquivos através de facilidades como browse, edit e outros utilitários.
Para se criar um arquivo no TSO, por exemplo, utilizam-se algumas telas pré-configuradas do ISPF/PDF. Por esta razão, é comum (mas não totalmente correto) que o programador se refira ao ISPF/PDF como TSO, e vice-versa.

Outra forma de programadores trabalharem com o TSO/E é digitando diretamente seus comandos no terminal, uma linha de cada vez, de forma semelhante ao que se faz no Bash do Unix, no CMD do Windows ou no Terminal do MacOS. Grande parte das funções executadas via linha de comando estão disponíveis em telas do ISPF/PDF. Em algumas situações, porém, utilizar a linha de comando pode ser mais prático e rápido.
A interface do TSO é do tipo texto. Toda a navegação se dá através do teclado. O usuário precisa de um terminal da família 3270 ou de um emulador de terminal TN3270 para trabalhar com o TSO.
Logon
Cada usuário recebe dos administradores do sistema um userid e uma password inicial para acessar o TSO. Essa password normalmente precisa ser alterada pelo próprio usuário no primeiro acesso. A política de segurança estabelecida pelos administradores do sistema estabelecem um prazo de validade para as passwords. Quando esse prazo expira, as passwords precisam ser alteradas novamente.
Também são os administradores do sistema que estabelecem as regras de formação dessas passwords: a quantidade mínima de caracteres; se devem ou não ter números, letras e caracteres especiais; quantos caracteres iguais podem ser usados em cada password; quantos caracteres repetidos podem ser iguais em passwords anteriores daquele usuário; se devem começar e terminar com letras ou números e assim por diante.
ROSCOE
O Roscoe (Remote OS Conversational Operating Environment) é um ambiente on-line não-IBM para interação com o sistema operacional z/OS. Ele executa basicamente as mesmas funções do TSO.
O Roscoe foi desenvolvido pela Applied Data Research em 1970, e hoje é comercializado pela Computer Associates.
Existem instalações disponibilizam apenas o Roscoe para seus desenvolvedores, e alguns administradores de sistema afirmam que ele consome menos recursos que o TSO. É comum, porém, que alguns ambientes disponibilizem tanto o Roscoe quanto o TSO, deixando a critério do desenvolvedor a escolha de qual ferramenta ele quer usar.
Como sempre acontece na área de TI, existem defensores de um produto ou outro, com longa argumentação técnica de cada lado para justificar suas escolhas. Para alguns, o Roscoe consome menos memória, consequentemente faz menos swap, e por isso é mais rápido. Para outros, o TSO é mais completo, mais flexível e cria um address space para cada usuário, o que o torna mais estável.
Assim como o TSO, o Roscoe permite a criação, edição, consulta, cópia e deleção de data sets. Permite também editar e compilar programas, e submeter jobs. Mas enquanto no TSO a interação acontece através de menus e painéis do ISPF/PDF, no Roscoe essa interação acontece por linhas de comando e mensagens do sistema.
Quando você abre uma sessão no Roscoe ele automaticamente cria uma área de trabalho exclusiva chamada de AWS (active work space). Você pode inserir, alterar ou excluir linhas no AWS diretamente no terminal, ou copiar para o AWS linhas que estão em armazenadas em outros data sets. Você pode também salvar seu AWS num outro data set.
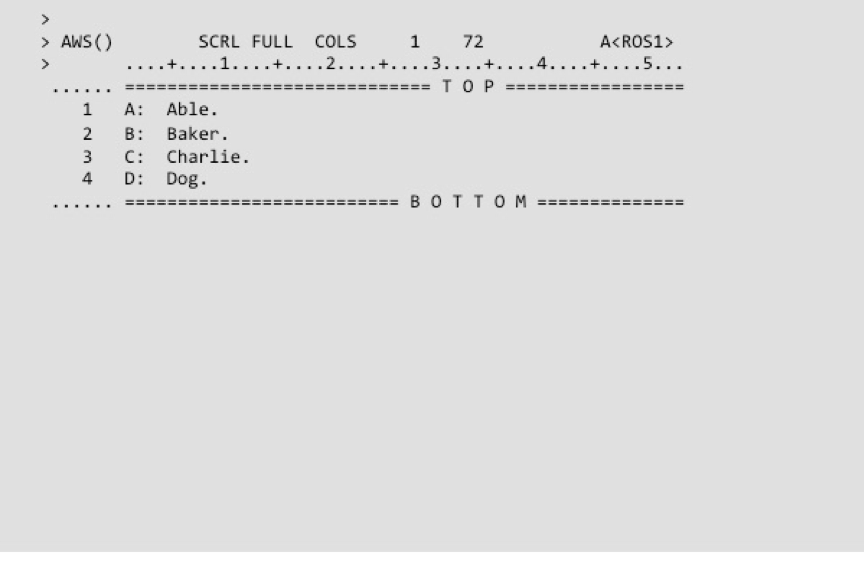
Assim, por exemplo, um desenvolvedor pode copiar para o AWS um programa fonte que está em um arquivo particionado, alterar esse programa, salvá-lo no próprio AWS e depois exportá-lo de volta para o particionado.
Se você encerrar uma sessão do Roscoe, ou se houver uma queda na rede ou falha de sistema, todos os dados que estiverem no AWS serão salvos automaticamente num particionado individual chamado Roscoe Library (ou ROSLIB). O AWS será salvo como um membro desse particionado e receberá um nome no formato SAVAWSnn, onde nn será um identificador único. Na próxima vez que você abrir novamente uma sessão no Roscoe, você poderá usar esses membros para recuperar seu AWS.
JES
JES, ou Job Entry System, é o sistema utilizado no z/OS para executar jobs batch. Todos os jobs submetidos são colocados em uma fila única e vão sendo processados de acordo com as regras definidas pelos administradores do sistema.
Os jobs submetidos pelos usuários (operadores, desenvolvedores ou analistas de produção) passam por diversas fases ou tratamentos dentro do JES, desde a sua chegada até sua conclusão e eliminação. Cada fase tem sua própria fila de tratamento dentro do JES; quando o job passa por uma fase, ele é colocado na fila da fase seguinte.
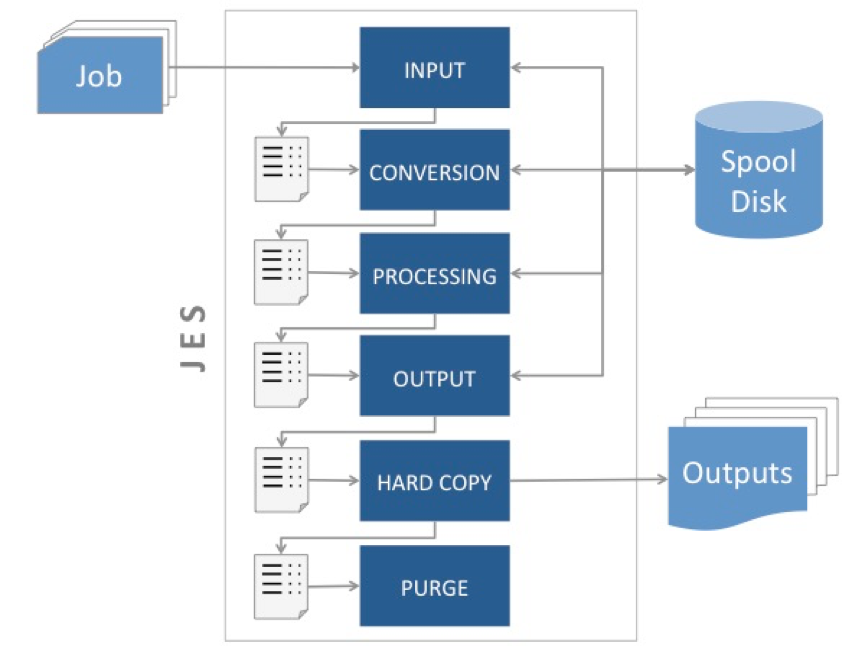
Na fase INPUT, o JES recebe um job submetido pelo usuário. Este job pode estar armazenado num arquivo ou num membro de arquivo particionado. O job também pode ter sido submetido por outro programa, normalmente um scheduler, que o transmitiu para uma das internal readers gerenciadas pelo JES. Também nesta fase o JES atribui um identificador para o job e para cada linha JCL codificada neste job. Todas as informações recebidas e/ou geradas na fase de input são armazenadas num data set interno chamado spool disk. Estas informações ficam disponíveis neste spool disk para serem repassadas para as próximas fases.
Na fase CONVERSION, o JES analisa todos os comandos codificados no job, valida sua sintaxe e incorpora procedures externas que eventualmente tenham sido mencionadas pelo programador. Depois disso o job é convertido para o formato esperado pelo JES. Este formato executável é então armazenado no spool disk para ser usado na fase seguinte.
Na fase PROCESSING, o JES envia os próximos jobs da fila para os initiators que estão livres. Um initiator é um programa que faz parte do sistema operacional mas é controlado pelo JES. O initiator é responsável por disponibilizar os recursos solicitados pelo job (arquivos, discos, fitas, impressoras…) permitindo que sua execução comece. Initiators podem ser criados manualmente pelos operadores ou automaticamente pelo JES, no momento em que ele é iniciado.
Na fase OUTPUT, o JES salva no spool disk todas as informações geradas pelo job ou para o job. Essas informações podem ser data sets ou relatórios gerados pelos programas executados pelo job; mensagens do sistema que o desenvolvedor pediu que fossem salvas, mensagens de erro etc.
Na fase de HARD-COPY, o JES recupera as informações de saída que foram salvas na fase anterior e as direciona para os dispositivos e/ou data sets definitivos que foram informadas pelo desenvolvedor no momento da codificação do job.
Na fase de PURGE, o espaço destinado ao spool disk é eliminado e uma mensagem é enviada para o operador informando que o processamento foi concluído.
O desenvolvedor interage com o JES através de comandos que ele insere no próprio job e dos relatórios que o JES gera após o processamento. Esses comandos são usados, por exemplo, para solicitar prioridade de execução, enviar uma mensagem específica para o operador, ou definir o número de cópias de determinado relatório.
Os comandos do JES têm precedência sobre os comandos do JCL. Se um job possui um comando JCL definindo um parâmetro de execução e esse mesmo job tem um comando JES que afeta esse parâmetro, o valor que foi estabelecido pelo JES é que será utilizado.
O z/OS possui dois sistemas bastante semelhantes para cumprir as funções do JES. Eles são conhecidos como JES2 e JES3. Existem diferenças significativas no funcionamento interno desses dois sistemas, que está fora do escopo deste livro. Para o desenvolvedor, a diferença aparece principalmente no uso de alguns comandos JES dentro de seus jobs: alguns comandos só funcionarão se o job for executado no JES2, enquanto outros só funcionarão no JES3.
CICS
Mainframes são capazes de executar simultaneamente milhares de jobs batch, processando grandes volumes de informação. Mas, além disso, também oferecem capacidade para processar milhares de transações on-line ao mesmo tempo.
O Customer Information Control System (CICS) é o software produto mais usado em sistemas operacionais z/OS para gerenciamento de transações on-line. O CICS disponibiliza serviços que permitem que uma mesma aplicação, usando a mesma base de dados, possam ser executados ao mesmo tempo por milhares de usuários.
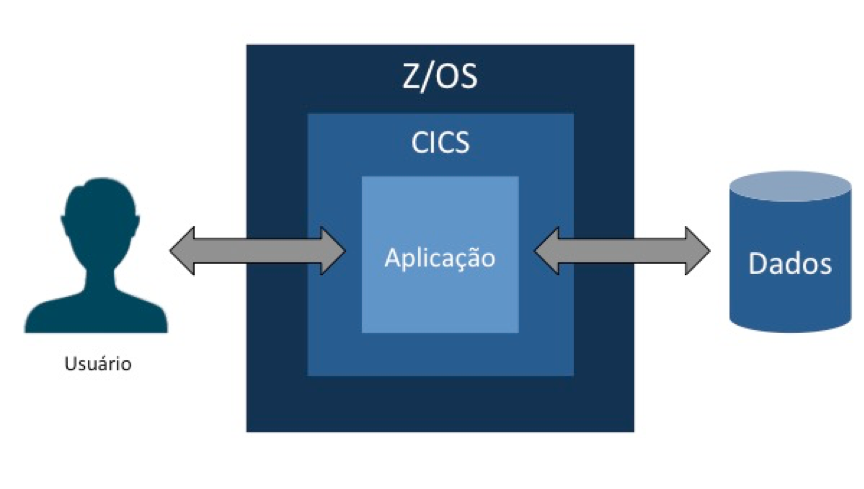
Uma aplicação CICS é um conjunto de programas relacionados que, juntos, permitem ao usuário executar uma operação de negócio: cadastrar clientes e produtos, registrar vendas, lançar movimentação de estoque etc.
O z/OS normalmente tem mais de uma instância do CICS rodando na máquina ou no LPAR. Cada instância é executada em seu próprio address space.
O CICS permite ao desenvolvedor separar regras de negócio, lógica da aplicação e uso de recursos. Para isso, utiliza quatro conceitos fundamentais:
- Transação: Para o CICS, uma transação é um pedaço de processamento realizado a partir de uma solicitação única. Na maioria das vezes essa solicitação é enviada por um usuário a partir de um terminal, mas ela também pode vir de uma página web, de um web service etc. Cada transação do CICS possui um nome de quatro caracteres. Esse nome precisa ser cadastrado pelos administradores do sistema numa tabela conhecida como PCT, ou program control table. Recentemente a indústria de TI passou a usar o termo “transação” para se referir às unidades de recuperação de uma aplicação, isto é, o conjunto de operações que podem ser confirmadas ou desfeitas a qualquer momento pela aplicação. No mundo do CICS, porém, essa unidade de recuperação é chamada de “unidade de trabalho”, como mencionaremos mais adiante.
- Programa Aplicativo: Uma transação é formada por um ou mais programas aplicativos que, quando executados, processam a função esperada da transação.
- Unidade de Trabalho: Conjunto de operações que podem ser confirmadas ou desfeitas a qualquer momento, por decisão da aplicação ou por uma falha no sistema.
- Tarefa: O termo “tarefa” também é usado na indústria de TI para expressar conceitos diversos. E mesmo na plataforma mainframe algumas vezes usamos essa expressão para descrever jobs batch, por exemplo. Mas para o CICS o conceito de tarefa é semelhante à ideia de threads, em outras plataformas. Quando o CICS recebe uma solicitação para executar uma transação, ele inicia uma tarefa para atender a essa instância de execução, muitas vezes com data sets exclusivos, para atender um único usuário. Quando o processamento da transação termina, a tarefa é encerrada pelo CICS.
Grande parte das instalações usam o COBOL para interagir com o CICS e implementar suas transações on-line. Mas outras linguagens podem ser utilizadas, tais como, PL/I, Assembler, C, C++ ou Java.
A interação do programa com o CICS se dá por comandos específicos que fazem parte do CICS Command Level Programming Interface e seguem o formato “EXEC CICS”. Para programas escritos em Java, no entanto, deve-se usar uma classe específica conhecida como JCICS.
Programas Conversacionais e Pseudo-conversacionais
Numa programação conversacional, o programa estabelece uma “conversa” com o usuário, mostrando ou solicitando informações e aguardando uma resposta do usuário para continuar seu processamento. Esse tipo de programação é o mais intuitivo para a maioria dos desenvolvedores acostumados com outras plataformas.
A figura 36 mostra um exemplo de programação conversacional. Em algum momento o programa mostra uma tela para o usuário e solicita que ele preencha um campo. O usuário então preenche o campo e tecla <ENTER>. O programa recebe o campo preenchido pelo usuário, busca uma informação na base de dados e exibe uma tela de resposta para o usuário.
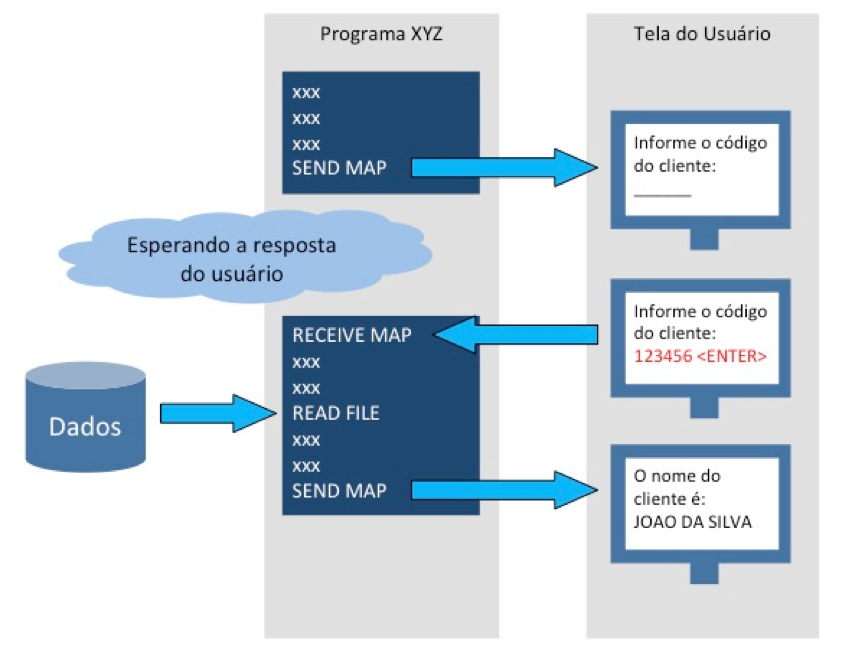
Na programação conversacional, o programa está sempre disponível, aguardando a resposta do usuário e mantendo os recursos que foram abertos e que serão necessários para a continuidade de sua execução. A decisão de liberar ou não os recursos (para não prendê-los) cabe ao programador em tempo de codificação.
Na programação pseudo-conversacional isso não ocorre. Cada trecho do programa é na verdade uma transação independente, que processa uma solicitação específica, responde ao usuário e depois termina (e é eliminada).
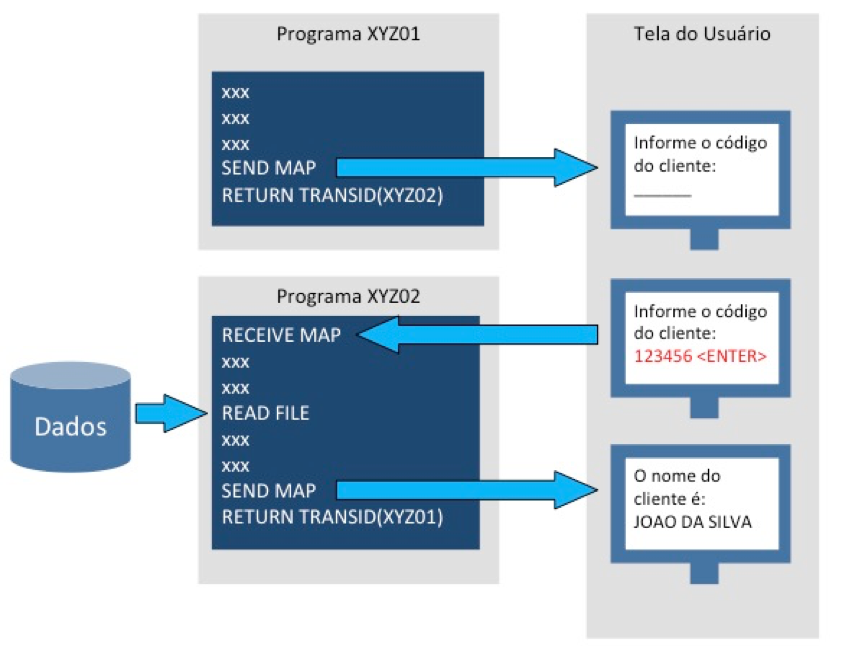
Esse modelo de programação recebe esse nome porque dá a impressão para o usuário de que ele está operando um programa conversacional tradicional, quando na verdade ele está navegando por uma sequência de programas não-conversacionais. O comando RETURN TRANSID, codificado em cada programa, informa ao CICS qual a próxima transação que deverá ser chamada depois que o usuário responder.
Programas pseudo-conversacionais, portanto, podem ser mais eficientes quanto ao uso de recursos do sistema, pois não dependem que o programador decida, em tempo de codificação, quais recursos devem ser liberados.
DB2
Por muitos anos o DB2 esteve disponível apenas para mainframes. Mas a partir dos anos 1990 surgiram versões para diferentes sistemas operacionais: Linux, Unix, Windows, i5/OS (anteriormente chamado de OS/400), z/VSE, z/VM e, naturalmente, z/OS
Por esse motivo, de todos os conceitos, recursos e produtos mencionados nesse livro, talvez o DB2 seja o mais conhecido mesmo por aqueles que estão ingressando agora na plataforma mainframe. Nosso objetivo aqui será, portanto, apenas apresentar algumas informações específicas sobre o DB2 que está disponível para o sistema z/OS.
Os conceitos fundamentais sobre bancos de dados relacionais também não serão tratados aqui, uma vez que desenvolvedores com experiências em outras plataformas certamente já trabalharam com produtos baseados neste modelo. O conceito de coluna, índice, tabela de dados, view, query, QBE e SQL, por exemplo, é o mesmo, seja no Oracle, no Microsoft SQL Server, Postgres, SQLBase ou MySQL.
Database
Database é o nome que o DB2 dá a um conjunto de tabelas, índices e views. É possível criar mais de um database numa mesma instância do DB2.
Table Spaces
Tabelas e views são apenas construções lógicas apresentadas pelo sistema gerenciador de banco de dados (SGBD). Os dados estão efetivamente armazenados em estruturas chamadas de table spaces. Fisicamente, um table space é um conjunto de um ou mais arquivos VSAM.
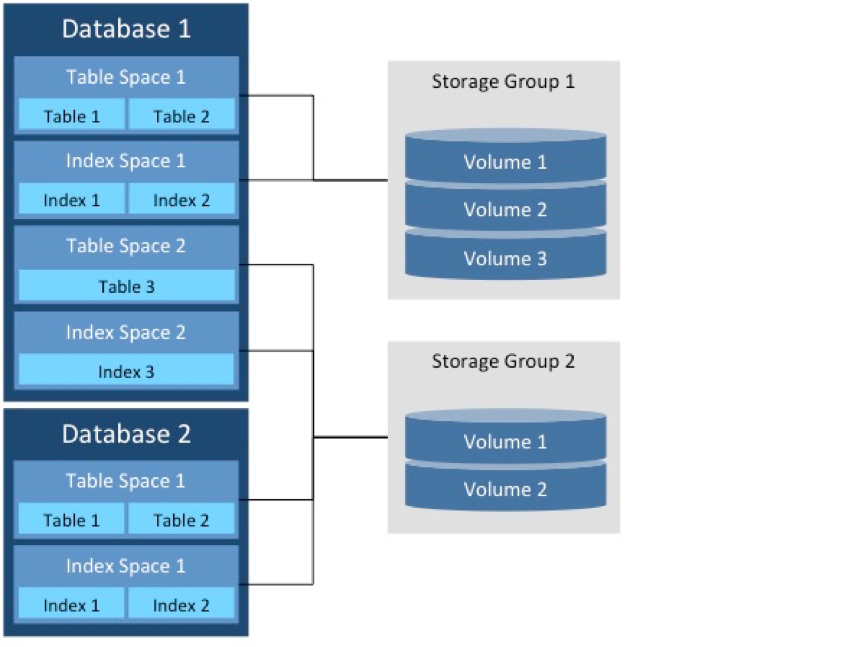
Um table space pode conter dados de uma ou mais tabelas de dados, mas muitos DBAs (e os próprios manuais da IBM) recomendam que cada table space contenha dados de uma única tabela.
Table spaces são divididos em unidades chamadas páginas. As páginas de um table space possuem sempre um mesmo tamanho (4K, 8K, 16K ou 32K). Uma operação de leitura ou gravação no DB2 sempre lê ou grava uma página inteira. A semelhança entre o conceito de página no DB2 e control interval no VSAM não é por acaso, uma vez que os dados lidos ou gravados pelo banco de dados estão, na verdade, armazenados em data sets VSAM.
Index Spaces
Index spaces são estruturas que armazenam informações sobre um único índice de terminada tabela de dados. Se uma tabela de dados possui mais de um índice, cada índice estará em um index space diferente.
Index spaces também são fisicamente organizados em data sets VSAM, e por isso estão baseados no mesmo conceito de página mencionado quando falamos de table spaces.
Storage Groups
Os data sets VSAM que compõem table spaces e index spaces são organizados em storage groups. Num storage group podem ser armazenados dados de diversos table spaces e index spaces. Essa estrutura permite ao DBA balancear a carga de trabalho entre diferentes unidades de disco, evitando gargalos de dispositivo e gargalos de canal.
Catálogo do DB2
O DB2 mantém um conjunto de tabelas especiais que contêm informações sobre tabelas de dados, índices e views criados em cada banco de dados. O conjunto dessas tabelas especiais é chamado de catálogo.
Quando você cria, altera ou elimina um objeto no DB2 – seja ele uma coluna, uma tabela, uma view, um índice ou um table space – o DB2 insere, atualiza ou deleta linhas dessas tabelas do catálogo.
Por exemplo, SYSIBM.SYSTABLES é uma dessas tabelas especiais. Ela armazena informações sobre as tabelas de dados que existem em todos os bancos de dados administradores pelo DB2, com colunas para nome, proprietário (owner), data de criação, nome do table space onde está armazenada etc. SYSIBM.SYSCOLUMNS, da mesma forma, contém informações sobre todas as colunas de todas as tabelas disponíveis nos bancos.
As tabelas do catálogo podem ser lidas como qualquer outra tabela do DB2. O desenvolvedor utiliza o SQL para acessá-las quando precisa conhecer a estrutura de determinada tabela de dados, os campos que compõem determinado índice ou mesmo os programas que acessam uma view específica. O DB2, no entanto, não permite que se faça INSERT, UPDATE, DELETE, TRUNCATE ou MERGE com essas tabelas.
SQL Estático
A linguagem utilizada para acesso ao DB2 é o SQL, como em quase todos os SGBDs relacionais.
O modo estático é o que normalmente acontece, por exemplo, quando um comando SQL é inserido num programa Cobol. O pré-compilador do SQL verifica a sintaxe, elimina eventuais comentários e transforma o SQL numa série de chamadas a subrotinas do DB2 que executarão a função desejada.
Essa execução, no entanto, seguirá um plano de acesso que é estabelecido também em tempo de compilação do programa. Na prática, isso significa que algumas decisões do banco de dados sobre como acessar os dados serão tomadas na hora em que o programa é compilado, e esse mesmo procedimento (ou plano) será repetido sempre que o programa for executado.
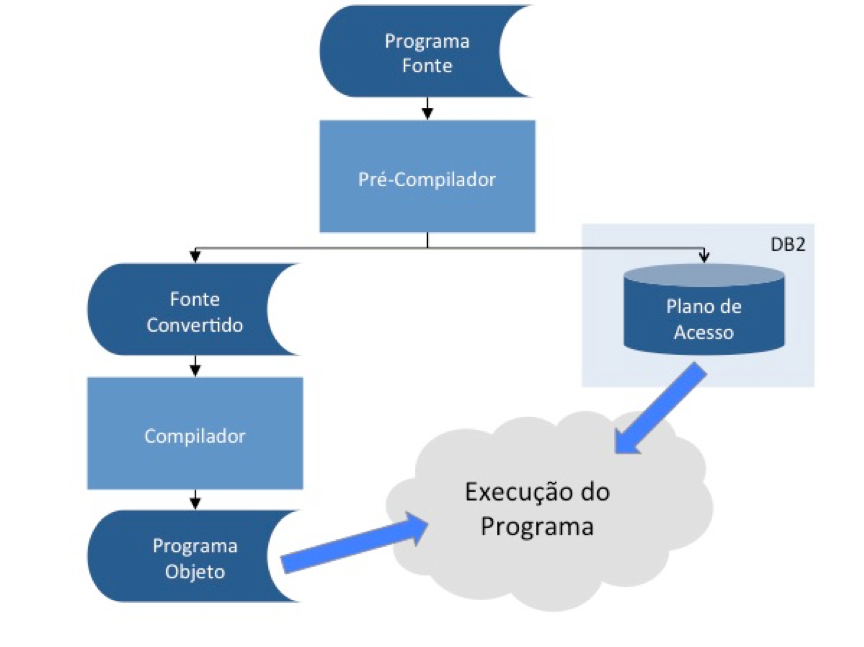
Isso implica em algumas questões fundamentais para os desenvolvedores. Suponha, por exemplo, que você construa um programa para acessar uma tabela de dados que contém apenas cinco registros.
Seu programa deverá selecionar os registros que contêm um determinado valor numa coluna que faz parte de um índice. No momento da compilação, o DB2 certamente tomará a decisão de ignorar a existência do índice e ler sequencialmente os registros da tabela para encontrar aqueles que você quer.
Ele fará isso porque ler os cinco registros sequencialmente é mais rápido do que ler um index space para localizar o valor que você forneceu e depois ler o table space para encontrar os registros de dados correspondentes.
Imagine agora que logo depois de você compilar e testar o programa alguém resolva carregar a tabela com seus dados definitivos. Digamos, 10 milhões de registros. Se seu programa utilizou SQL estático, o plano original que o DB2 gerou em tempo de compilação será repetido, e seu programa lerá sequencialmente todos os 10 milhões de registros para encontrar aqueles que você quer, numa operação conhecida como table scan.
O DB2 utiliza as informações do catálogo para tomar suas decisões no momento da geração do plano. Por esse motivo, se você recompilar seu programa após a carga de 10 milhões de registros, ele certamente buscará outra solução: aí sim lendo primeiro o index space para só então localizar os registros de dados que você procura, no table space.
Esse é um exemplo bastante simplista sobre as implicações do SQL estático. Diversas outras possibilidades precisam ser consideradas pelos desenvolvedores em tempo de especificação, construção e teste de aplicações que usam bancos de dados relacionais. No entanto, o SQL estático tem suas vantagens. Em muitas situações deixar o banco de dados tomar suas decisões em tempo de execução (como seria no caso do SQL dinâmico) implicaria em obrigar o banco a validar sintaxe, compilar comandos, analisar o catálogo e gerar instruções a cada vez que o comando SQL fosse executado dentro do programa.
SQL Dinâmico
No modo dinâmico, o plano de acesso do DB2 é gerado em tempo de execução. O esforço de execução exigido do DB2 é maior, como mencionamos no parágrafo anterior, mas algumas situações precisam desse modo de execução.
Por exemplo, eventualmente um programa pode permitir que o próprio usuário monte sua query. Neste caso, o mais comum seria compor o comando SQL a partir das opções do usuário e preparar esse comando em tempo de execução. Desta forma, o DB2 geraria um novo plano de acesso a cada preparação do comando.
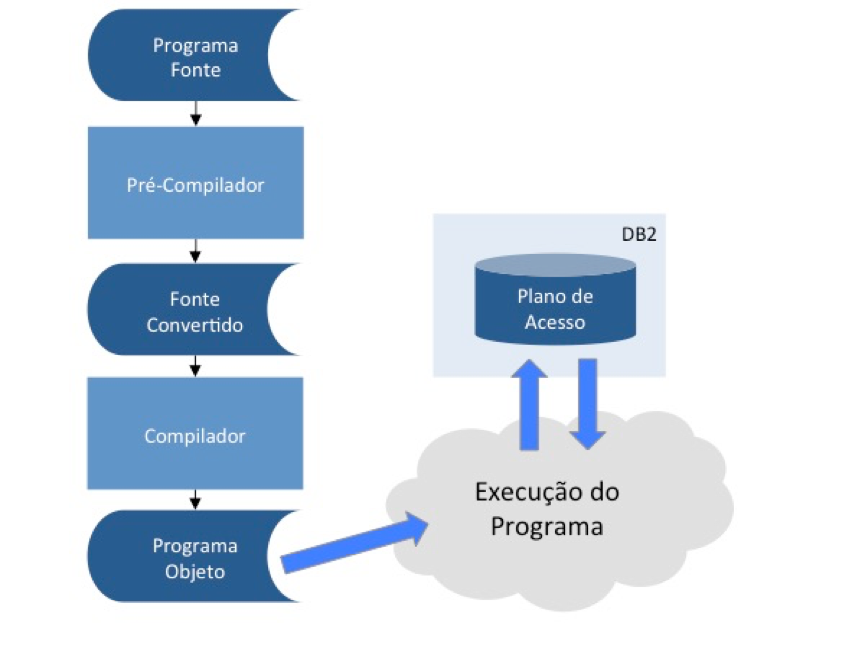
O SQL dinâmico pode ser uma solução para o caso de programas que acessam tabelas muito voláteis, isto é, tabelas com crescimento (ou diminuição) imprevisível e com uma estrutura complexa de índices. Deixar o DB2 avaliar a situação dessa tabelas na hora da execução minimizaria as grandes variações de performance que poderiam ser percebidas no modo estático.
Utilitários e ferramentas
Diversos utilitários e ferramentas estão disponíveis no z/OS para permitir que os desenvolvedores acessem os bancos de dados gerenciados pelo DB2.
O SPUFI (SQL Processing Using File Input) é um utilitário que normalmente os administradores de sistema disponibilizam no ISPF (TSO) para programadores e analistas. Essa ferramenta é muito usada por DBAs para conceder ou revogar acessos, mas também é útil para desenvolvedores testarem suas queries antes de inseri-las nos programas.
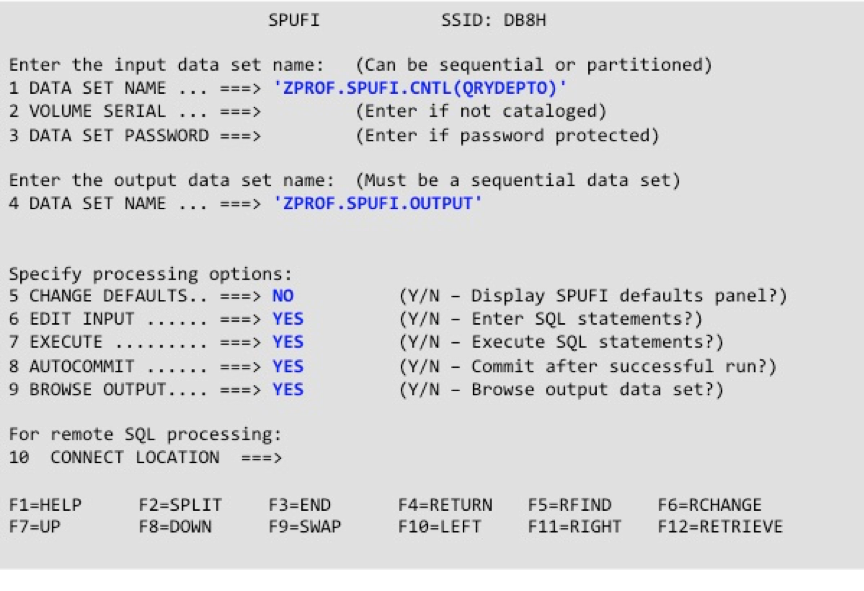
O SPUFI usa arquivos para entradas e saídas. Normalmente as queries são criadas num particionado (cada query é um membro do particionado) e o resultado da execução é gravado num data set simples, que depois pode ser consultado pelo desenvolvedor.
Outra ferramenta que você pode encontrar no mainframe é o QMF (Query Management Facility), com o qual o desenvolvedor pode construir, salvar e executar queries sobre um banco de dados. O QMF permite também que o desenvolvedor crie e salve formatos de relatórios que poderão ser aproveitados em outras queries.
ADABAS
Adaptable Data Base System (ADABAS) é outro SGBD frequentemente encontrado em mainframes. Ele foi desenvolvido na década de 1970 pela empresa alemã Software AG, que dentre outros produtos fornece também a linguagem de programação NATURAL, sobre a qual falaremos mais adiante.
Assim como no DB2, existem edições do ADABAS para diferentes sistemas operacionais: z/OS, BS2000, OS/400, Unix, Linux, Windows e OpenVMS. No Brasil, tanto o ADABAS quanto o NATURAL foram adotados em muitas instituições públicas: bancos federais e estaduais, empresas de telecomunicação (que eram estatais), agências e secretarias de governo etc.
Enquanto num banco de dados relacional falamos em tabelas, linhas e colunas, no ADABAS nos referimos a arquivos, registros e campos. Essa diferença não é apenas uma convenção de nomes: um arquivo ADABAS não precisa seguir regras de normalização, e por isso muitos consideram que ele é um SGBD não-relacional.
Como todo SGBD, o ADABAS oferece para o usuário uma visão dos arquivos e seus registros que não necessariamente corresponde à forma como esses dados são armazenados fisicamente.
Os arquivos criados no banco ficam num conjunto de data sets chamados coletivamente de DATA. Nesta área estão tanto as informações de negócio quanto algumas informações de controle do próprio banco (identificação do banco, dicionário, cadastro de usuários etc.)
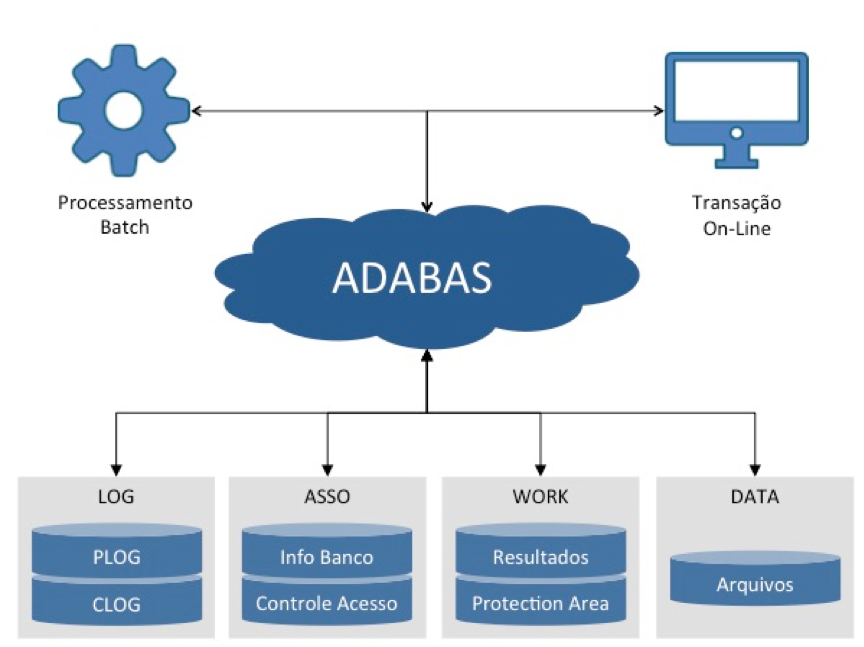
Os campos que compõem cada arquivo, seus relacionamentos, as listas invertidas para localização de registros e as autorizações/restrições de acesso ficam num conjunto de data sets conhecidos como ASSO (de associator).
O ADABAS também mantém um conjunto de data sets para armazenar as atualizações sofridas pelo banco (protection log ou simplesmente PLOG) e todas as atividades dos usuários (command log ou CLOG).
Os campos que formam um registro ADABAS podem ser alfanuméricos, binários, numéricos de ponto fixo, numéricos de ponto flutuante, numéricos decimais compactados, numéricos decimais descompactados e texto.
Os campos também podem ser classificados como elementares, periódicos, grupos ou grupos periódicos. Os campos elementares podem assumir apenas um valor dentro do registro. Os campos periódicos, ao contrário, podem receber diversos valores num mesmo registro. Um grupo é um campo formado por dois ou mais campos elementares. E um grupo periódico é um conjunto de grupos que podem assumir múltiplos valores.
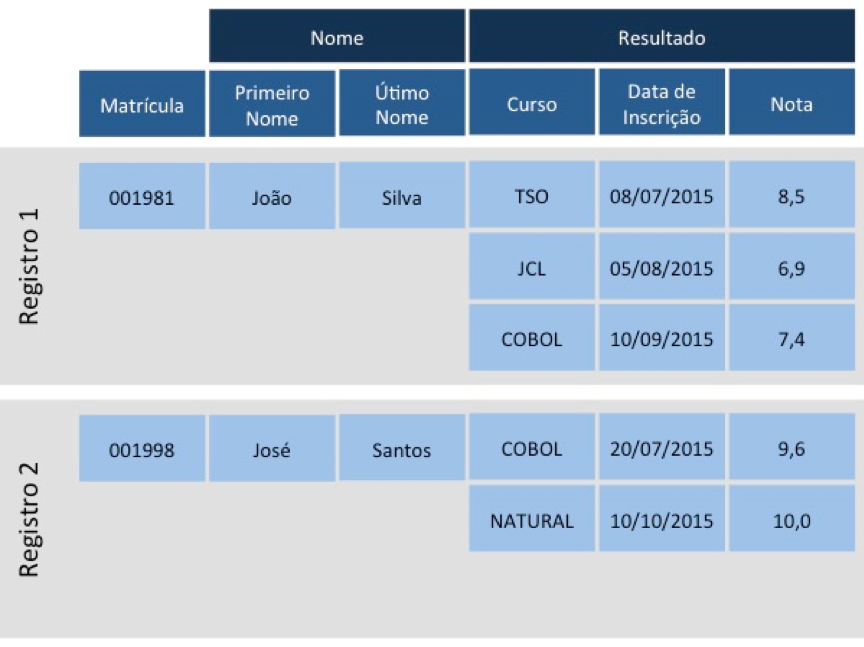
A figura 43 mostra um arquivo hipotético de alunos. Os campos Matrícula, Primeiro Nome e Último Nome são elementares, pois assumem apenas um valor dentro de cada registro. O campo Nome é um grupo, pois é formado pelos campos elementares Primeiro Nome e Último Nome. Os campos Curso, Data de Inscrição e Nota são periódicos; eles assumem mais de um valor para o mesmo registro. E o campo Resultado é um grupo periódico, é formado por um conjunto campos periódicos.
O ADABAS atribui a cada registro um ISN (internal sequence number) que identifica unicamente o registro dentro do arquivo. Muitas vezes utilizamos o ISN para realizar operações de leitura, atualização e deleção de registros.
Campos que são usados frequentemente em pesquisas e seleções podem ser definidos como descritores. Campos descritores são indexados em listas invertidas, acelerando os acessos. É possível criar descritores compostos por dois ou mais campos, e também descritores formados apenas por parte de um campo. No primeiro caso eles são chamados de superdescritores; no segundo, subdescritores.
IMS
O Information Management System (ou IMS) é um sistema que começou a ser desenvolvido pelas empresas IBM, Caterpillar e Rockwell em 1966 para o programa Apolo, da Nasa.
Ele é formado por dois componentes: um banco de dados (IMS/DB) e um gerenciador de transações (IMS/TM, também conhecido por seu nome anterior, IMS/DC). Esses dois componentes podem ser adquiridos separadamente, mas grande parte das instalações possuem os dois.
Novos serviços são desenvolvidos constantemente pela IBM para atender às novas interfaces e necessidades de comunicação das empresas. Como todos os outros produtos de software da IBM, serviços e recursos incluídos nas novas versões do IMS garantem a compatibilidade com os sistemas anteriores.
As aplicações que utilizam os serviços do IMS podem ser escritas em diversas linguagens. As mais comuns são Cobol, PL/I e Rexx, mas é possível desenvolver aplicações em Assembler, C, Pascal e outras. Os programas se comunicam com o IMS através de um conjunto de funções normalmente chamado de DL/I (data language/interface).
IMS/DB
O IMS/DB é um SGBD que adota um modelo hierárquico para armazenar e acessar informações. Na terminologia do IMS/DB, registros de informações são chamados de segmentos.
Para explicar a terminologia e alguns conceitos do IMS/DB vamos usar um modelo como exemplo, mostrado na figura 44. Imagine um banco de dados para armazenar informações sobre projetos em andamento. Cada projeto pode ser executado por uma ou mais equipes, que por sua vez são formadas por uma ou mais pessoas. Todos os projetos são divididos em etapas, e cada etapa é formada por uma ou mais tarefas. Uma etapa é considerada concluída quando todos os produtos esperados são concluídos.
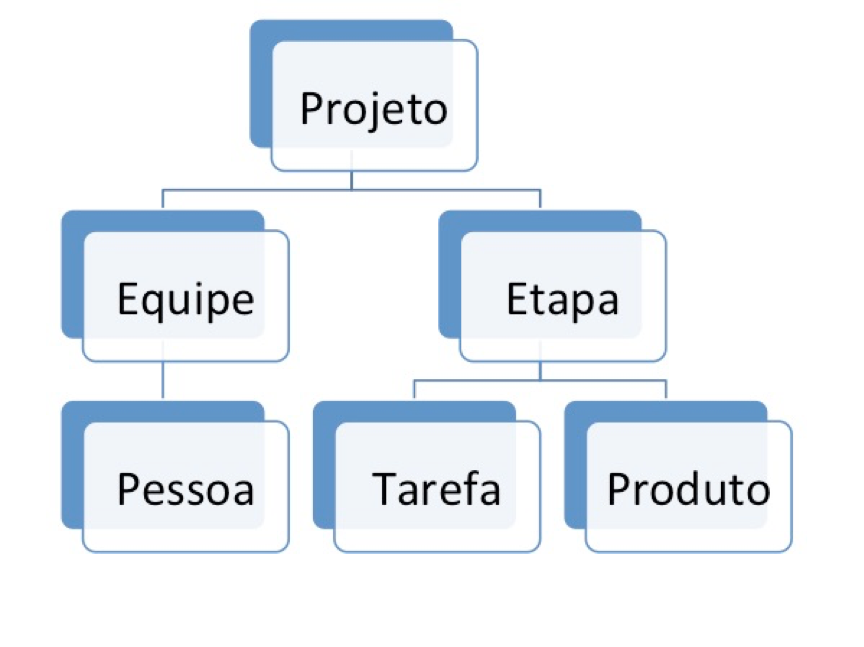
O termo tipo de segmento se refere à categoria ou classe de dados que são armazenados em determinado segmento. No nosso banco de dados hipotético teríamos seis tipos de segmento: projeto, equipe, etapa, pessoa, tarefa e produto.
No IMS/DB o segmento mais alto na hierarquia é chamado de segmento raiz. Ele é o único que não possui um segmento pai. Todos os outros segmentos, com exceção do segmento raiz, são chamados de segmentos dependentes.
Uma vez carregado o banco de dados, cada instância dos segmentos são chamados de ocorrências de segmento. Assim, seguindo no mesmo exemplo, se o projeto “X” possui as equipes “alfa”, “beta”, “gama” e “delta” então “alfa” seria uma ocorrência do segmento equipe, “beta” seria outra ocorrência desse mesmo segmento e assim por diante.
O conjunto formado por um segmento raiz e todos os seus segmentos dependentes é chamado de database record, ou simplesmente registro. Se no banco de dados que usamos como exemplo houver informações sobre 12 projetos, dizemos que esse banco possui 12 registros, independentemente da quantidade de ocorrências de segmento que existam nas entidades equipe, pessoa, etapa, tarefa e produto. Ao ler o registro do projeto “Y”, todos os segmentos dependentes do projeto “Y” serão recuperados.
O IMS/DB permite dois tipos de acesso: sequencial e randômico.
No acesso sequencial, o banco de dados é lido registro a registro. Apenas para efeito de ilustração, podemos dizer que dentro de cada registro os segmentos são recuperados de cima para baixo, e da esquerda para a direita. A tabela abaixo mostra um exemplo do que poderiam ser as primeiras leituras sequenciais nosso banco de dados hipotético:
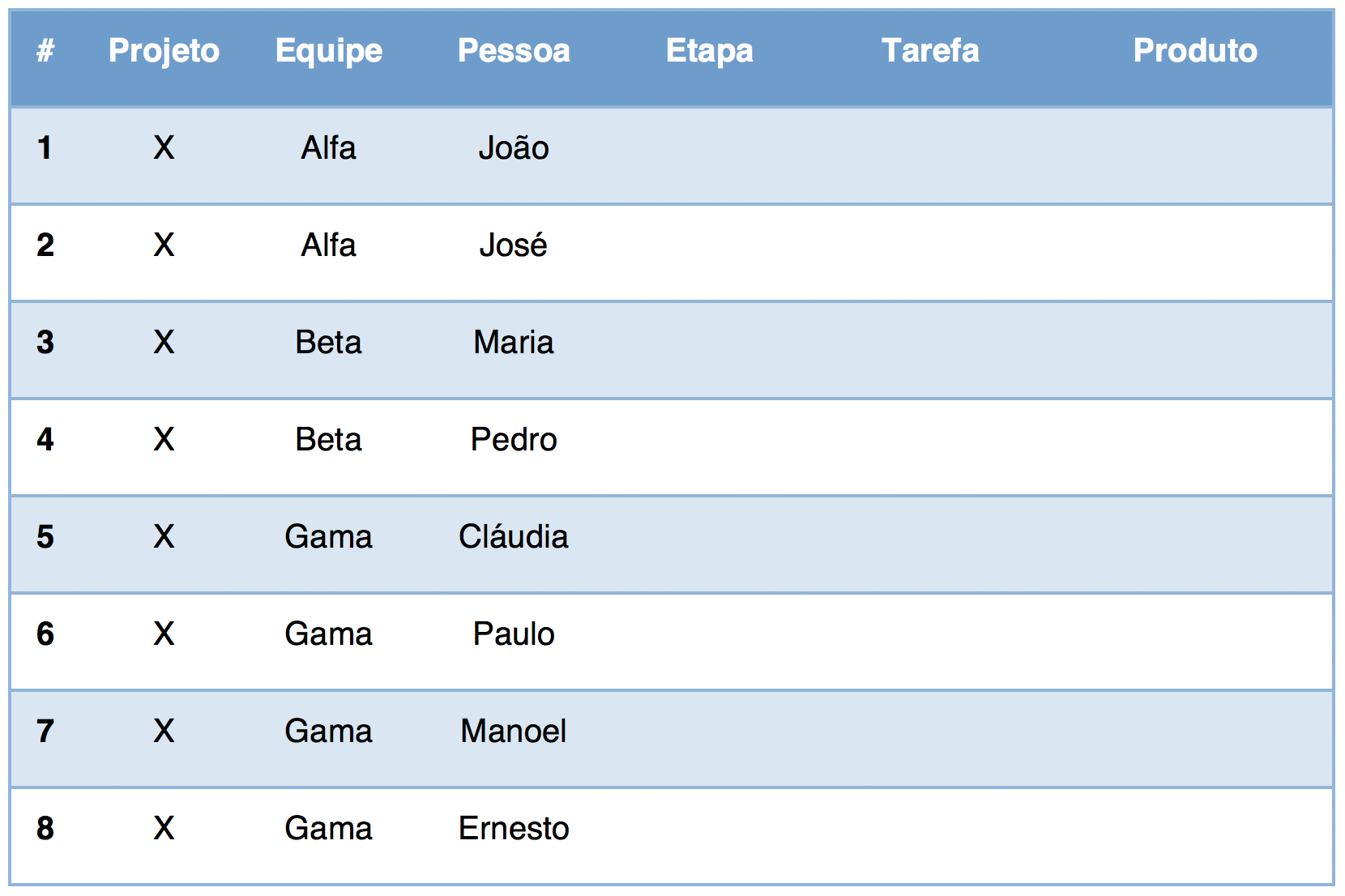
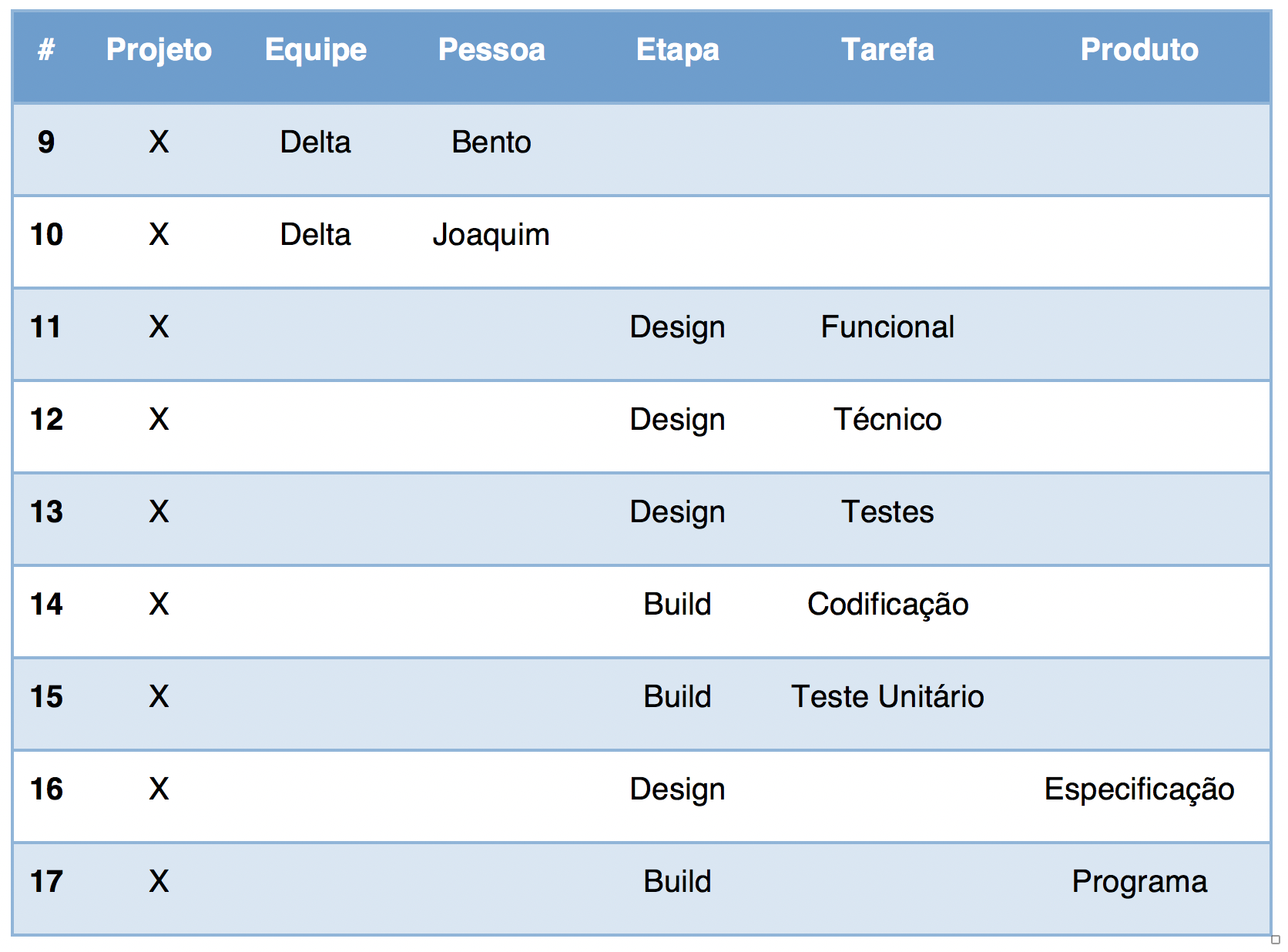
Repare que o tipo de segmento Etapa só começou a ser lido depois que todo o caminho Projeto-Equipe-Pessoa foi concluído. Da mesma forma, o tipo de segmento Produto só começou a ser lido depois que todas as ocorrências Projeto-Etapa-Tarefa foram recuperadas.
O acesso randômico, diferentemente, é executado quando fornecemos uma chave concatenada. Todo segmento possui um campo chave (key field, também chamado de sequence field). Por exemplo, idProjeto, idEquipe e idPessoa poderiam ser campos chaves dos segmentos Projeto, Equipe e Pessoa, respectivamente. Para acessar diretamente a linha 8 da tabela anterior, sem ter que passar por todas as anteriores, poderíamos fazer um acesso randômico fornecendo a chave concatenada {X, Gama, Ernesto}.
Quando um programa aplicativo acessa o IMS/DB, os segmentos e campos acessados e as operações que pretende executar (inclusão, alteração, exclusão ou consulta) são definidos em componente chamado program communication block (ou PCB). O conjunto de todos os PCBs utilizados pelo programa é chamado de program specification block (ou PSB). O PSB é uma entidade externa ao programa, e é carregado pelo IMS quando o aplicativo é iniciado.
IMS/TM (ou IMS/DC)
O IMS Transaction Manager é um gerenciador de transações que conecta camadas de apresentação a aplicações de negócio através de um modelo de mensagem e enfileiramento.
Uma transação, em sua forma mais simples, começa com uma entidade externa enviando uma mensagem para o IMS/TM, solicitando a execução de uma função ou serviço. O IMS inicia e executa o(s) programa(s) correspondente(s) ao serviço solicitado, que por sua vez vão gerar alguma informação. Essa informação é então enviada pelo IMS para a entidade externa que solicitou o serviço.
Essas entidades externas (que podem ser um usuário num terminal remoto, um web service que se comunica com o IMS via TCP/IP ou um programa aplicativo rodando em outro address space) podem enviar uma ou mais mensagens de uma só vez. No contexto do IMS, esse conjunto de mensagens é chamado de transmissão.
O IMS/TM pode receber mensagens solicitando entrada de dados, saída de dados, a execução de um comando específico ou ainda o processamento de um programa. Todas as mensagens são enfileiradas e tratadas de forma assíncrona pelo IMS. Essa solução garante uma alta capacidade de processamento ao IMS, que pode, por exemplo, atender a uma solicitação de entrada de dados do usuário A ao mesmo tempo em que executa um programa solicitado pelo usuário B.
Outros Sistemas Operacionais
O z/OS não é o único sistema operacional que pode ser instalado em mainframes ou em LPARs, e cada sistema operacional possui características, específicas e finalidades distintas.
Quatro desses sistemas são mais comuns, e merecem ser mencionados: z/VM, z/VSE, Linux on System/Z e z/TPF.
z/VM
O z/VM, ou z/Virtual Machine, é o sistema operacional mais indicado para implementar a virtualização de servidores em mainframes. Com o z/VM uma empresa pode, por exemplo, criar de milhares de servidores Linux consolidando toda a sua server farm num único equipamento físico.
Este sistema foi lançado no ano 2000, junto com o System/Z, mas tem sua origem nos sistemas operacionais da linha VM que a IBM lançou e desenvolve desde 1972.
O z/VM possui dois componentes principais:
- O Control Program (ou CP) é responsável por criar as máquinas virtuais e compartilhar os recursos físicos do equipamento com essas máquinas virtuais. Todos os recursos reais do mainframe podem ser compartilhados pelo CP: processadores, memória, canais, unidades de disco, impressoras etc.
- O Conversational Monitor System (ou CMS) é o front-end que permite a interação do usuário com uma das máquinas virtuais. O CMS pode ser completamente reconfigurado pelo usuário, pois todas as modificações realizadas só terão efeito na máquina virtual que ele está operando.
Podemos concluir que no z/VM, o CMS não pode existir sem o CP, mas o contrário é verdadeiro. Na verdade, é possível instalar o VM/CP no equipamento e colocar sistemas operacionais diferentes (do CMS) em cada máquina virtual: Linux, z/VSE, z/TPF ou mesmo o z/OS.
Quando apenas o z/VM está disponível no equipamento (o que é raro hoje em dia), o sistema operacional é normalmente chamado de “VM nativo”.
Em mainframes com VM nativo é possível instalar o CICS para tratar transações on-line, mas o mais comum sempre foi utilizar linguagens conversacionais, como o CSP. Da mesma forma não existe um JCL para o z/VM; processos batch são normalmente codificados na linguagem Rexx.
z/VSE
O sistema operacional z/VSE é uma evolução do sistema DOS que fez parte das máquinas da família System/360.
Comparado ao z/OS, o z/VSE oferece uma solução menor e menos complexa principalmente para processamento batch. Na prática, a maioria das empresas mantém o z/VSE rodando em uma ou mais máquinas virtuais criadas no z/VM. O CMS, do z/VM, é usado nesses casos como ambiente para desenvolvimento e manutenção de aplicações que rodem no z/VSE.
No z/VSE, transações on-line são processadas pelo CICS ou pelo MQ Series, como no z/OS. Processos batch, que são os mais comuns no z/VSE, são codificados numa linguagem de controle também chamada de JCL, mas que mantém diferenças significativas com o JCL do z/OS.
Os clientes normalmente migram suas aplicações para o z/OS quando crescem além da capacidade do z/VSE.
Linux on System/Z
Diversas distribuições não-IBM do Linux podem ser usadas nos mainframes System/Z: Red Hat, Suse e Ubuntu são alguns exemplos. A possibilidade de unir o enorme ecossistema open source do Linux com a segurança, confiabilidade e segurança dos mainframes tem contribuído bastante para a corrida para a virtualização.
O Linux no mainframe é executado em máquinas virtuais criadas no z/VM. O componente CP do z/VM atua como hipervisor, compartilhando todos os dispositivos físicos disponíveis no mainframe.
O CP também é responsável por intermediar algumas diferenças fundamentais de arquitetura entre a plataforma mainframe e o Linux, como por exemplo:
- O Linux trabalha com os tradicionais dispositivos de disco do tipo CKD/SCSI. Outros sistemas operacionais que rodam no mainframe reconhecem esses discos como propriedade do Linux, mas não podem ler ou gravar diretamente neles. O compartilhamento de informações entre o Linux e os outros sistemas operacionais se dá através de serviços disponibilizados pelo CP para as máquinas virtuais envolvidas.
- O Linux não usa o padrão 3270 para terminais, e sim terminais baseados no sistema X Windows ou emuladores X Windows em computadores pessoais.
- Sistemas Linux rodando sob o z/VM podem ser clonados rapidamente para gerar uma outra imagem do Linux. O z/VM emula uma LAN para conectar as diversas imagens do Linux, permitindo, por exemplo, que o tradicional diretório /usr seja compartilhado entre elas.
- O Linux no mainframe opera com caracteres ASCII, enquanto os sistemas operacionais do mainframe mantém seus dados em formato EBCDIC. Os próprios drivers do Linux for System/Z são responsáveis pela tradução dos caracteres quando as informações são transferidas de um lado para o outro.
Os sistemas que rodam no Linux em servidores dedicados podem migrar para as máquinas virtuais que rodam Linux no System/Z sem nenhuma alteração.
z/TPF
Se você já teve a oportunidade de observar uma operadora de companhia aérea consultando uma reserva num terminal, então muito provavelmente já viu o z/TPF funcionando. Esse sistema operacional talvez tenha a interface mais estranha e incomum, mesmo para os profissionais de TI mais experientes.
A interface com o usuário não é baseada nem em telas texto (como no z/OS, no z/VM ou no Unix) nem em telas gráficas (como no Windows ou no MacOS). Toda a comunicação entre o usuário e o sistema é feita por comandos de uma ou duas linhas, numa tela preta, que vai rolando para cima à medida em que os comandos são digitados. As respostas do sistema operacional também aparecem como uma ou duas linhas de texto, logo após os comandos enviados pelo usuário.
O z/TPF (Transaction Processing Facility) é um sistema operacional de uso específico, voltado para aplicações que possuem um volume extremo de transações on-line. Empresas operadoras de cartão de crédito e companhias aéreas possuem sistemas com essas características. É o sistema utilizado, por exemplo, por American Airlines, Alitalia, Japan Airlines, KLM, Air Canada, Holliday Inn, Sabre e Amadeus. Também é o sistema onde operam os serviços de autorização da Visa e da American Express.
Esse sistema operacional foi projetado para responder a milhares de mensagens por segundo, atendendo a redes remotas com dezenas de milhares de terminais e estações de trabalho. O tempo de resposta do z/TPF é frequentemente menor do que três segundos, do momento em que uma mensagem é enviada por um usuário até o momento em que esse usuário recebe a resposta do sistema. Ele também foi projetado para garantir máxima disponibilidade.
O z/TPF é um sistema utilizado exclusivamente para ambientes de produção. Todo o desenvolvimento e manutenção de aplicações é realizado em ambiente z/OS, z/VM (CMS) ou Linux e então exportado para o z/TPF.
| Anterior | Conteúdo | Próxima |