Source Code Slicing: o desafio da containerização do COBOL

Não tem muito tempo, por conta própria, eu botei um sistema em COBOL para rodar num container Docker. A experiência me ajudou a aprender um pouco sobre essa tecnologia, mas também me mostrou que o caminho para aproveitar os verdadeiros benefícios da containerização exigiria mais esforço.
Neste artigo eu pretendo discutir um pouco dos desafios que precisam ser enfrentados por sistemas legados escritos em COBOL para que eles efetivamente embarquem nessa jornada núvens híbridas, escalabilidade e automação.
Em linhas gerais, containerização é…
…uma forma de virtualização de sistema operacional que permite que uma aplicação seja executada em um espaço de endereçamento isolado chamado container.
Diferentemente da virtualização tradicional – onde cada unidade virtual possui sua própria cópia de sistema operacional – na containerização, todos os containers em determinado servidor compartilharão o próprio sistema operacional desse servidor, o que torna essa abordagem mais leve e, consequentemente, escalável e mais eficiente.
Tudo que faz parte da aplicação (binários, bibliotecas, arquivos de configuração e dependências) precisa estar encapsulado e isolado no seu próprio container.
Mas se o sistema A precisa chamar surotinas do sistema B, sabendo-se que A e B estarão em containers diferentes, essa chamada deverá acontecer através de algum protocolo de comunicação remoto: algo como um Remote Program Calling, um Sockets ou uma API RESTful.
Em outras palavras, “A” não dá call em um subprograma de “B”; “A” deve consumir um serviço de “B”.
E aí começa a complicar para o COBOL
Vamos pensar num programa COBOL típico, daqueles que foram construídos há mais de 30 anos e que, juntos com dezenas de milhares de outros programas semelhantes, seguem vivos e fortes.
Nesse programa típico, podemos ter uma camada de apresentação definida na SCREEN SECTION, uma validação de dados que acontece em alguns parágrafos do próprio programa; funcionalidades lógicas (como cálculos) processadas por outros parágrafos ou por algum subprograma chamado via CALL; e uma camada de interação e persistência de dados, executada por alguns comandos EXEC SQL codificados também no próprio programa.
Um monolito. A figura abaixo pretende fazer uma representação gráfica disso que acabei de comentar:
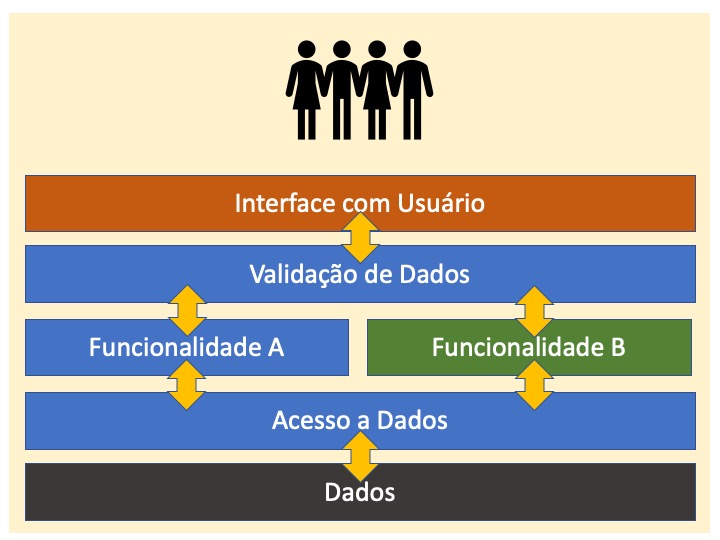
Na Figura 1, o retângulo amarelo representa o espaço de endereçamento do usuário. Você pode pensar num servidor onde todas as partes do programa estão sendo executadas, talvez com exceção da camada de dados.
Em um processo de containerização, a primeira camada a ser separada das demais seria exatamente a interface com o usuário. Ainda que tecnicamente seja possível fazer um usuário “logar” num container e executar um programa, essa tecnologia não foi desenhada para que centenas ou milhares de usuários estivessem logados e consumindo recursos desse espaço de endereçamento, que afinal foi pensado para ser o mais leve possível.
Além disso, cada solução de containerização, seja ela Docker ou Red Hat Open Shift, possui seu próprio conceito de “usuário”. De maneira simplista, para o Docker, quem está executando programas, scripts e comandos dentro do container é sempre o root; para o Red Hat Open Shift é um usuário randômico. Em ambos os casos, para que se pudesse “logar” num container como um usuário específico seria necessário replicar um arquivo /etc/passwd em cada imagem de aplicação, o que obviamente não seria uma boa ideia.
Outro aspecto que teria que ser levado em conta é o isolamento das aplicações em containers distintos. Claro que é possível colocar todos os 10.000 programas dos sistemas A, B e C rodando num mesmo container, mas, de novo, isso perderia toda flexibilidade, escalabilidade e possibilidade de automação que a containerização promete.
Por isso, imagine que na figura anterior a “Funcionalidade B” seja um subprograma de outro sistema. Nesse caso, esse outro sistema estaria em outro container, e seu subprograma não poderia simplesmente ser chamado via CALL pelo programa principal.
O fatiamento do código fonte
Source Code Slicing, ou fatiamento do código fonte, é uma abordagem que já vem sendo utilizada em diversos contextos, e que começa a ser considerada para resolver o problema da containerização de aplicações monolíticas.
Na verdade o que ela espera é oferecer algum método controlado para tranformar o programa típico da Figura 1, em algo parecido com a figura abaixo:
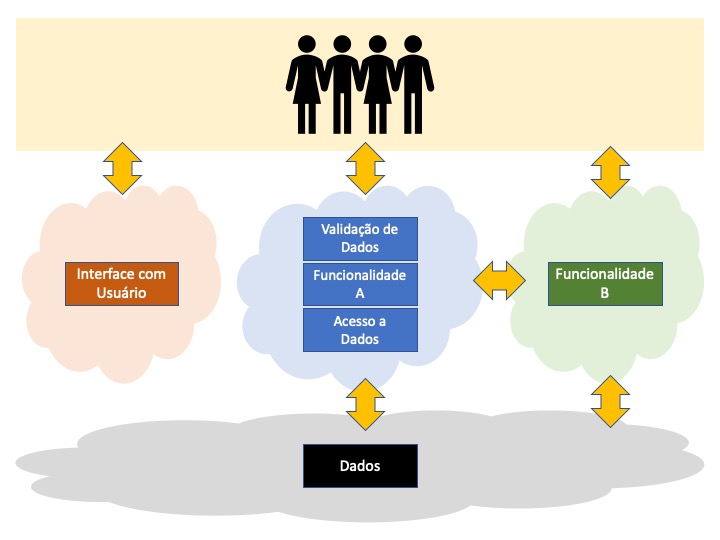
A interface com o usuário poderia estar no espaço de endereçamento dos usuários, mas também poderia ser oferecida como um serviço fornecido por um servidor de transações rodando num container.
O processo de validação de dados, a “funcionalidade A” e o acesso a dados estariam num segundo container. E a tal “funcionalidade B”, que fazia parte de outro sistema, agora está no container desse outro sistema.
O ponto aqui é que essa comunicação entre o container azul e o container verde, assim como a comunicação entre usuários e containers, não ocorre mais como no modelo anterior. Toda essa comunicação se dá através de APIs RESTful, usando por exemplo protocolos JSON.
Esse tipo de comunicação entre as peças do sistema facilitará (e muito) a integração com outras plataformas. Qualquer sistema em Java, C ou PHP é capaz de “conversar” através de APIs RESTful. Portanto, num processo de modernização, decisões como keep-and-maintain e replace-and-retire poderiam ser tomadas com mais flexibilidade.
Logo, eu vejo três desafios principais postos na mesa quando se fala em containerização de sistemas escritos em COBOL:
- Estabelecer uma solução para a camada de apresentação: de que maneira a interface será oferecida ao usuário e integrada aos demais componentes do sistema.
- Planejar o fatiamento de sistemas e programas: o que pertence a quem? O que faz mais sentido deixar junto e o que é melhor deixar separado?
- Estabelecer o protocolo de comunicação entre as partes que serão separadas, levando em consideração possíveis integrações com outras plataformas, padrões e recursos de segurança.
O compilador Micro Focus Visual Cobol 5 permite a implementação de parses JSON, e a comunidade responsável pelo GnuCobol 3 (em desenvolvimento) está implementando essa funcionalidade.
Conclusão
Métodos para a containerização de programas COBOL são o próximo desafio para essa linguagem de programação que existe há quase 60 anos e continua essencial e estratégica para sistemas críticos de grandes organizações.
Aumentar sua capacidade de integração e viabilizar seu aproveitamento em ambientes de núvens públicas e híbridas, DevOps e load balancing não só é possível, como seguramente fará com que ela permaneça viva por muito tempo mais.

