3. Conceitos e Recursos Fundamentais

Mainframes têm seu próprio vocabulário técnico, cheio de acrônimos e siglas. Por trás deste vocabulário existem conceitos e recursos que todo profissional que atua com eles precisa conhecer.
Quando começamos a trabalhar com uma tecnologia diferente, é comum não entendermos algumas expressões e conceitos técnicos que são mencionados constantemente em reuniões, apresentações, e-mails ou nas simples conversas do dia a dia.
No universo dos mainframes existem recursos bem específicos, que não existem ou não têm tanto destaque em outras plataformas.
Neste capítulo, vamos explorar alguns desses conceitos e recursos. O objetivo aqui é permitir que você entenda os conceitos por trás dessas expressões que são mencionadas frequentemente pelas pessoas que atuam no ambiente mainframe.
IPL
Initial Program Load, ou IPL, é o nome que se dá à operação que copia uma imagem do sistema operacional do disco para a memória real e inicia a sua execução.
O IPL é o boot do mainframe. Mas diferentemente do que acontece em computadores pessoais e alguns servidores, o mainframe é projetado para ficar meses em funcionamento contínuo. Um mainframe utilizado num sistema bancário, por exemplo, pode “sofrer” apenas um ou dois IPLs por ano, às vezes menos.
Apenas situações muito específicas podem exigir que a administração do sistema reinicie o mainframe através de um IPL. É possível substituir diversos componentes de hardware, por exemplo, sem tirar a máquina do ar. Mas uma falha no sistema de alimentação de energia do equipamento ou a atualização do sistema operacional podem exigir um IPL.
Normalmente IPLs são planejados com muita antecedência, e informados às diversas áreas usuárias do mainframe para que possam se planejar.
IPLs são executados através de consoles específicas. Normalmente a console é um PC ou laptop que fica conectado diretamente à CPU e que pode ser utilizado apenas por analistas de suporte ou operadores previamente autorizados.
MIPS
A capacidade de processamento de um mainframe é frequentemente medida pela sua quantidade de MIPS. Essa sigla significa “milhões de instruções por segundo”, e representa a quantidade de instruções de baixo nível (instruções de máquina) que os processadores do mainframe são capazes de executar em um segundo.
No entanto, muita crítica se faz a essa unidade de medida. Sabe-se que a própria estrutura do processador, determina a quantidade de instruções necessárias para completar uma tarefa. Alguns processadores podem ser mais rápidos, mas exigir uma quantidade maior de instruções de baixo nível para cada tarefa. Comparar computadores diferentes pela quantidade de MIPS, portanto, não faz muito sentido se eles adotam processadores de arquiteturas diferentes.
Esta unidade de medida, no entanto, é bastante utilizada pela própria indústria de hardware e software para estabelecer preços para licenças, aluguéis ou serviços de manutenção.
Por esse motivo, de vez em quando ouvimos que nossa empresa ou nosso cliente quer iniciar um “projeto para redução de MIPs”. A princípio, não faz muito sentido uma organização querer reduzir sua própria capacidade de processamento. Mas quando entendemos que muitos dos custos operacionais estão associados à “mipagem” dos equipamentos, aí compreendemos seus verdadeiros objetivos.
EBCDIC
Todo computador armazena informações como números binários e convertem esses binários em caracteres, sinais de pontuação e outros símbolos.
Quase todos os computadores do mercado utilizam o padrão ASCII para converter números em caracteres. No PC ou no Mac, por exemplo, a letra “A” corresponde ao número decimal 65, que corresponde ao binário 01000001.
Mainframes são diferentes. Eles adotam um padrão de oito bits chamado EBCDIC (Extended Binary Coded Decimal Interchange Code) que foi apresentado pela IBM no lançamento do System/360. Na tabela de conversão do EBCDIC, o caracter “A” corresponde ao decimal 193, que corresponde ao binário 11000001.
Curiosamente, nos anos 1960 a IBM fazia parte do comitê que viria a criar a codificação de sete bits que posteriormente ficou conhecida como ASCII. No entanto, não havia tempo hábil para preparar os periféricos do System/360 para esse novo padrão. A IBM optou então por expandir um padrão que já usava em equipamentos anteriores
Essa incompatibilidade gera ainda hoje algumas confusões quando arquivos são transferidos entre mainframes e computadores de outras plataformas. Por exemplo, se um arquivo é transmitido em modo binário de um PC ou servidor Unix para um mainframe, ou vice-versa, todos os caracteres desse arquivo serão interpretados incorretamente pelo computador de destino.
Felizmente quase todos os utilitários para transferência de arquivos (via FTP, por exemplo) estão preparados para converter caracteres de uma tabela para a outra. Algumas versões mais novas de subsistemas do mainframe (TSO PDF/ISPF, por exemplo) conseguem ler e editar arquivos gerados tanto para ASCII quanto para EBCDIC. Os próprios equipamentos da plataforma z/Series contam com instruções de processador, em nível de hardware, para acelerar a conversão de caracteres.
Processamento on-line e processamento batch
A maior parte do processamento realizado pelos mainframes se divide em dois tipos: processamento on-line e processamento batch.
Processamento on-line é um método de desenvolvimento de sistemas onde um usuário fornece interage com um programa. O programa solicita uma informação, o usuário fornece a informação solicitada, e o programa mostra o resultado. Esse é o modo que estamos mais habituados a encontrar no nosso dia a dia. Um programa projetado para funcionar seguindo este princípio é normalmente chamado de “programa on-line.
Em mainframes, no entanto, o processamento batch (ou em lote) tem uma importância maior do que se costuma observar em outras plataformas. Como uma das maiores características do mainframe é sua capacidade de processar grandes quantidades de informação, muitos dos sistemas desenvolvidos para esta plataforma são desenhados para receber, validar, processar, armazenar e apresentar resultados “em lotes”, com um mínimo de intervenção de usuários ou operadores;
Processamento batch é, portanto, um método de desenvolvimento de sistemas onde uma série de programas serão executados sequencialmente para processar informações agrupadas em lotes, ou arquivos.
Esses programas são executados, sem intervenção de usuários ou operadores, sempre numa mesma sequência. A ordem dos programas e as regras de execução são definidas pelo analista de sistema e codificadas na linguagem JCL, sobre a qual falaremos mais adiante.
O usuário ou operador normalmente não acompanham a execução da tarefa. Os resultados da execução são mostrados no final do processamento de todos os programas, em um ou mais relatórios conhecidos como SYSOUTS.

Exemplo de processamento batch
Para entender melhor o conceito de processamento batch, vamos analisar um caso prático, bastante parecido com os jobs que encontramos nos sistemas desenvolvidos em plataforma mainframe. Usaremos como exemplo uma rotina de tarifação de chamadas telefônicas, semelhante àquelas que encontramos em empresas operadoras de telecomunicação.
A rotina diária de tarifação é responsável por estabelecer o valor de cada chamada telefônica realizada no dia anterior por todos os assinantes da operadora. Literalmente, existem dezenas de milhões de chamadas que precisam ser processadas no rotina diária.
Mas existem diversos outros sistemas e jobs diários que precisam ser executados depois que a tarifação é concluída. Por esse motivo, o tempo disponível (a “janela de produção”) para processar a rotina de tarifação é de uma ou duas horas. Se levar mais do que isso, as demais rotinas diárias podem se acumular e comprometer o schedule de produção.
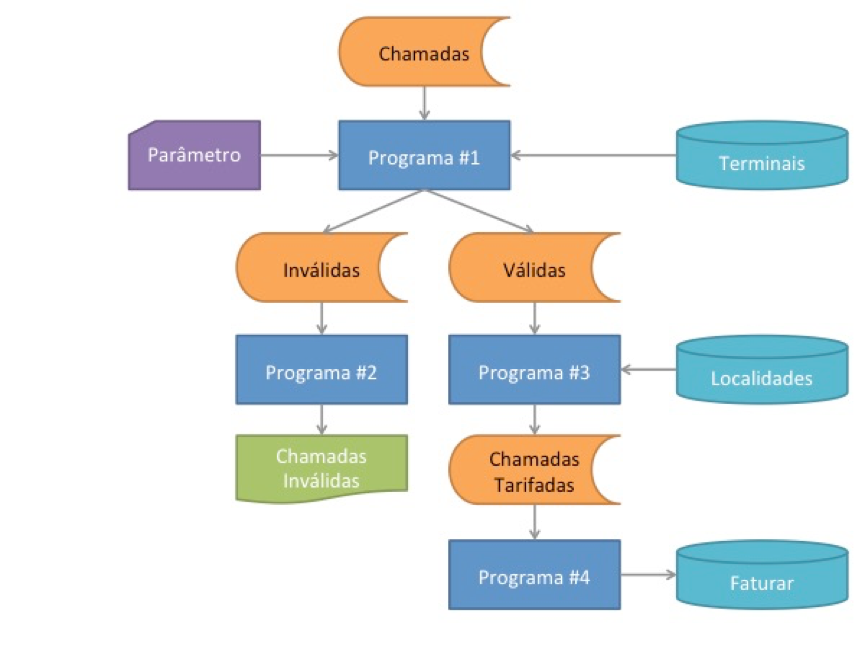
Para esta rotina, nosso analista de sistemas hipotético pensou em quatro programas:
- Programa #1: Lê o arquivo que contém as chamadas realizadas no dia anterior. Para cada registro lido, lê uma base de dados de terminais válidos e gera dois arquivos: um arquivo com as chamadas inválidas (cujo número de telefone não foi encontrado na base de terminais) e um arquivo com as chamadas inválidas (cujo número de telefone foi encontrado na base de terminais). Este programa recebe um parâmetro de execução que determina o percentual aceitável de chamadas válidas. Se a quantidade de chamadas inválidas for maior que esse percentual, o programa provoca um término anormal (chamado abend, ou abnormal end) que interromperá a execução do job impedindo que os demais programas sejam executados;
- Programa #2: Lê o arquivo que contém as chamadas inválidas geradas pelo programa anterior, e gera um relatório de chamadas inválidas que será analisados pelos usuários do sistema de tarifação.
- Programa #3: Lê o arquivo que contém as chamadas válidas geradas pelo primeiro programa. Para cada chamada lida, acessa uma base de dados para identificar a localidade onde estão instalados o telefone que originou a chamada e o telefone que recebeu a chamada. A distância entre as duas localidades determina o preço que será cobrado pela chamada. Depois de estabelecer o valor da chamada, o programa #3 gravará um arquivo com todas as informações do arquivo lido, mais as informações sobre localidades e tarifas que serão cobradas.
- Programa #4: Lê o arquivo de chamadas tarifadas, e grava todos os registros lidos em uma base de dados que posteriormente será lida para gerar a conta telefônica mensal.
Alguns comentários sobre a rotina do exemplo
- Todo o processamento ocorre sem intervenções de usuários ou operadores. O job é codificado em JCL e publicado em um scheduler. O scheduler é um software utilitário que permite estabelecer, dentre outras regras, quando os jobs serão executados e quais as pré-condições de execução (por exemplo, que jobs devem ter sido executados com sucesso antes dele).
- Um bom analista buscará fragmentar um job em diversos programas pequenos. Naturalmente, toda a funcionalidade definida para nossa rotina hipotética de tarifação podia ter sido codificada em um único programa. A manutenção de programas maiores, porém, é invariavelmente mais complexa, consome mais tempo e está sujeita a erros. A prática de quebrar o problema em programas menores facilita manutenções futuras, além de diminuir o acoplamento funcional do sistema.
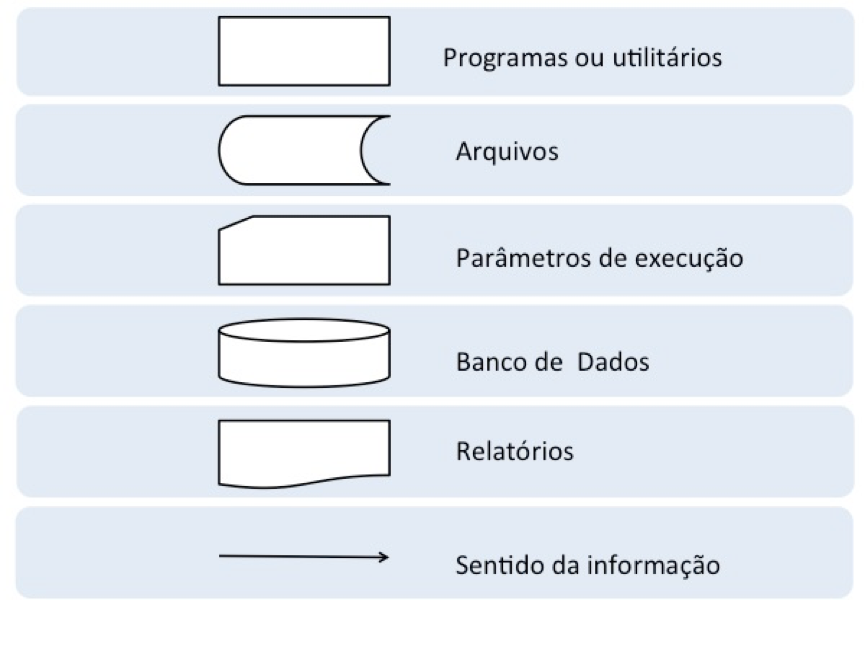
- A elaboração de um fluxograma para representar a estrutura do job é uma prática bastante comum em muitas organizações. Não existe um consenso absoluto sobre as regras usadas na elaboração desses fluxogramas. Nada parecido com o rigor da UML, por exemplo. Mas alguns símbolos foram se consolidando ao longo do tempo. Em nosso exemplo aparecem alguns desses símbolos, que podem ser vistos na figura 16.
- As setas não indicam a ordem de execucão dos programas, mas sim o uso que os programas fazem de cada componente do job. O primeiro programa, por exemplo, lê o arquivo de chamadas, recebe o limite de chamadas inválidas toleráveis, lê uma tabela do banco de dados que contém os terminais e grava dois arquivos de saída: um com as chamadas válidas e outro com as chamadas inválidas. Em outras palavras, as setas indicam se as informações entram ou saem dos programas.

Em um mainframe de produção existem centenas de jobs sendo executados simultaneamente, 24 horas por dia. O planejamento dessas execuções, inclusive estabelecendo quais jobs podem ser executados ao mesmo tempo, é realizado pelo analista do sistema com a orientação do analista de produção.
Memória Real, Memória Virtual e Address Space
Os primeiros mainframes, inclusive aqueles que já adotavam a arquitetura System/360, permitiam alguma forma de compartilhamento de recursos entre programas concorrentes. E um dos maiores desafios para os programadores era o compartilhamento de memória.
Foi só com a chegada do System/370®, nos anos 1970, que os computadores de grande porte passaram a adotar uma solução comercial que tornava esse compartilhamento transparente para o programador.
A solução encontrada foi a criação de uma memória virtual, mantida pelo sistema operacional. O conceito de memória virtual permitia também que um programa fosse executado em um computador que tivesse uma quantidade de memória real (física) menor que o espaço exigido pelo programa.
A memória virtual pode ser implementada de diversas formas. Nos mainframes, adotou-se um conceito conhecido como “espaço de endereçamento”, ou address spacing.
Address Space é um conjunto de endereços virtuais que o sistema operacional reserva para cada programa executado.
O sistema operacional cria diversas páginas de 4K em disco ou em outra unidade de armazenamento. A quantidade de páginas criadas pelo sistema operacional é maior do que a quantidade de páginas existentes na memória física do computador. Quando um programa é executado, o sistema operacional posiciona seus dados e instruções em uma ou mais páginas de memória virtual. E essas páginas só são transferidas para a memória real quando um dos processadores do equipamento dedicar uma parte de seu tempo a esse programa.

Linha de Memória e RMODE
Algumas vezes você ouvirá que determinado programa precisa rodar “abaixo da linha de memória” ou “abaixo da linha de 16”. Mas o que isso significa?
A quantidade de endereços virtuais que o address space consegue mapear está diretamente ligada à arquitetura do equipamento, e essa capacidade cresceu com a evolução da plataforma.
As versões mais recentes do sistema operacional z/OS trabalham com endereços de 64 bits. Isso permite endereçar 18.446.744.073.709.600.000 de bytes (ou 16 exabytes).
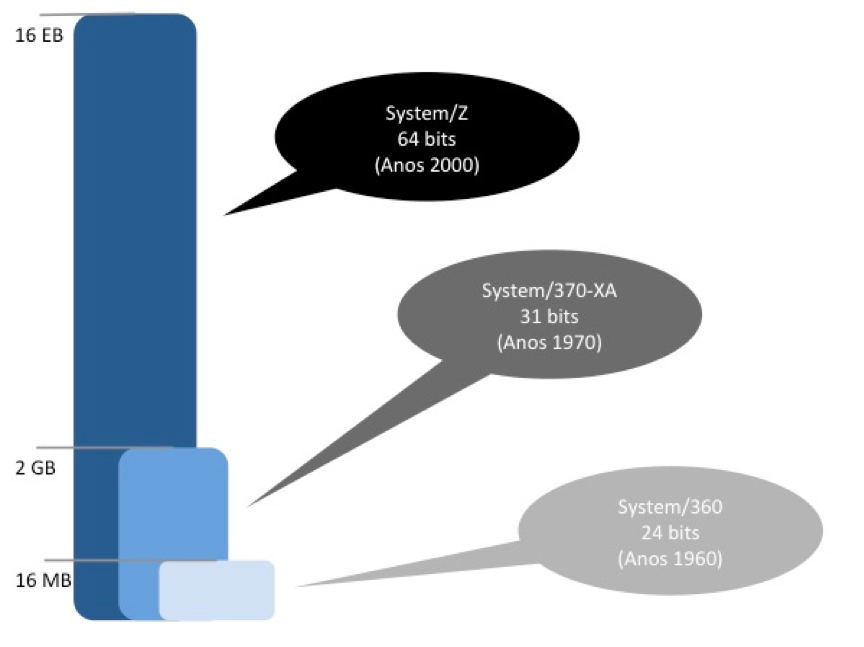
Fisicamente, um mainframe pode ter muito menos memória física do que isso, mas o address space mantido pelo sistema operacional pode simular esses 16 exabytes em memória virtual, permitindo que muito mais programas sejam executados ao mesmo tempo.
No entanto, ainda existem muitos programas que foram construídos décadas atrás e que ainda estão funcionando. Na grande maioria dos casos, basta recompilar esses programas na nova arquitetura para que eles possam aproveitar os novos recursos e a maior capacidade dos equipamentos mais novos.
Mas se esses programas foram construídos fazendo referência direta às posições de memória real, então provavelmente o sistema operacional não poderá “aloca-los em qualquer lugar”. Muitos programas escritos em Assembler caem nessa situação.
Para garantir a compatibilidade com versões anteriores, os sistemas operacionais do mainframe adotam um conceito conhecido como residence mode, ou simplesmente RMODE.
Quando um programa é carregado com RMODE=24, significa que ele é restrito à arquitetura de 24 bits. O sistema operacional sabe, nesse caso, que precisará carregar dados e instruções desse programa em algum lugar “abaixo da linha de 16 MB”.
A mesma situação acontece com programas que foram construídos depois do lançamento da arquitetura System/370-XA (que introduziu pela primeira vez o endereçamente em 31 bits). Se esses programas fazem referência direta às posições de memória, então precisam ser compilados com RMODE=31, para que o sistema operacional carregue seus dados e instruções “abaixo da linha de 2 GB”.
Mainframes da arquitetura System/Z possuem address spaces com endereços de 64 bits. A grande maioria dos programas (que não caem nas duas situações anteriores) são compilados com RMODE=64 para aproveitar toda a capacidade de memória disponível.
Paginação e SWAP
O sistema operacional usa uma série de tabelas para determinar se uma página de memória usada por determinado programa está na memória real ou na memória virtual. Quando precisa acessar um dado ou instrução do programa, o sistema operacional procura o endereço da página virtual nessas tabelas, transfere o conteúdo para uma página disponível na memória real, executa as instruções e devolve o conteúdo para a memória virtual.
Esse movimento de páginas entre memória virtual e memória real é conhecido como paginação e é transparente para o usuário.
Existem algumas situações, porém, em que os dados de determinado programa precisam desocupar temporariamente a memória real. Isso pode acontecer quando um programa com mais prioridade requisita memória real e não existam páginas disponíveis. Nesse caso, o sistema desocupará a memória real, baixando para a memória virtual todas as páginas de um programa com menos prioridade[1].
A operação de transferência temporária de todas as páginas de um programa da memória real para a virtual é conhecido como swap out. Quando o programa puder ser retomado, todas as páginas são novamente transferidas da memória virtual para a real. Essa operação é conhecida como swap in. O processo de swap in e swap out é genericamente chamado de swap ou swapping.
Analistas de suporte e administradores do sistema conseguem acompanhar a quantidade de swaps realizada pela máquina ao longo do tempo. Normalmente eles usam esses indicadores para avaliar problemas de dimensionamento de memória ou prioridades mal configuradas.
Multiprogramação e Multiprocessamento
Multiprogramação e multiprocessamento algumas vezes são mencionados como se representassem a mesma coisa. Na verdade, são dois processos diferentes que atuam juntos para garantir a máxima capacidade de processamento simultâneo do equipamento.
Os primeiros sistemas operacionais (nos mainframes da década de 1960 e nos PCs da década de 1980) se dedicavam a um único usuário de cada vez. Naquele tempo, o sistema operacional tinha uma fila de tarefas, executava a primeira tarefa da fila até o final e depois passava para a tarefa seguinte.
Os sistemas operacionais mais novos, em várias plataformas, conseguem executar vários programas simultaneamente através de um recurso conhecido como multiprogramação.
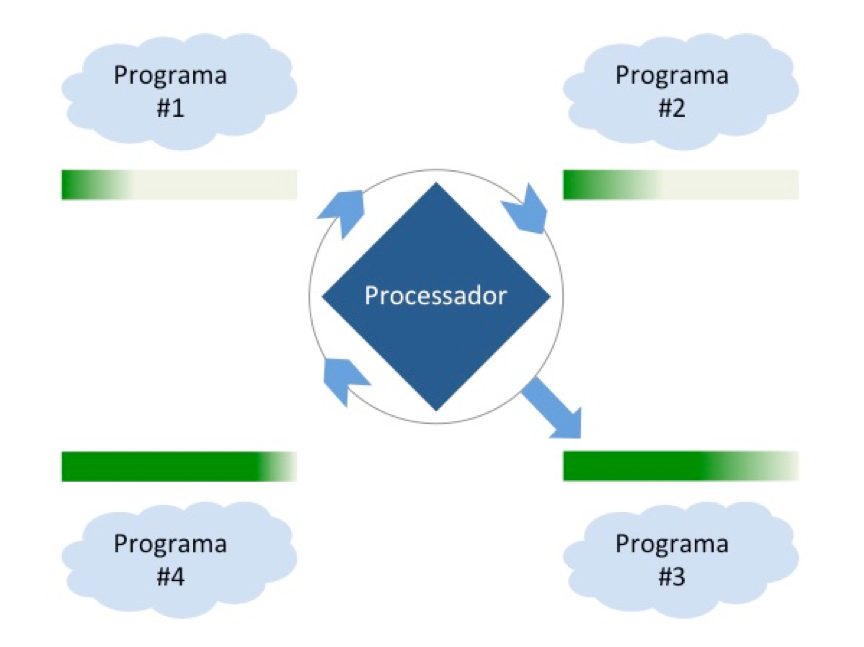
A multiprogramação permite que um programa ou processo seja interrompido temporariamente e retomado algum tempo depois. O sistema operacional captura e salva todas as informações relevantes do programa interrompido, permitindo que o processador se dedique temporariamente a outro programa. Quando o processador estiver disponível para retomar o programa interrompido, o sistema recupera as informações salvas e reinicia sua execução do ponto em que parou. Como todo esse processo é muito rápido (as fatias de tempo concedido a cada programa são medidas em milissegundos), cria-se a percepção de que todos os programas estão sendo atendidos ao mesmo tempo.
No multiprocessamento dois ou mais processadores fazem o trabalho de multiprogramação, compartilhando diversos recursos de hardware, tais como memória, dispositivos de armazenamento em disco, canais de comunicação etc.
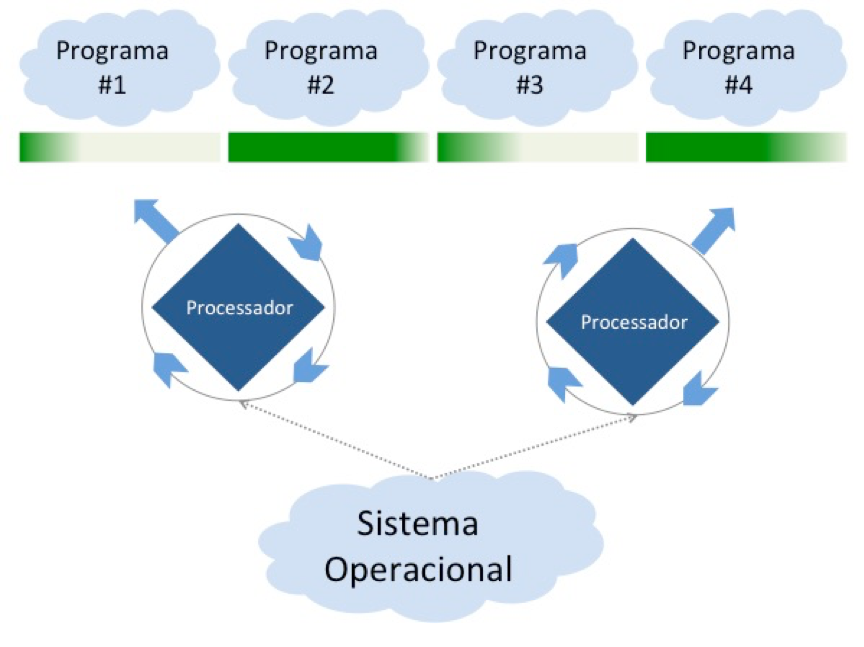
A combinação de multiprogramação em cada processador com o compartilhamento de recursos físicos proporcionado pelo multiprocessamento é que torna o mainframe a plataforma ideal para empresas com uma carga de trabalho elevado.
[1] Na prática os critérios utilizados pelo sistema são mais complexos do que isso.
| Anterior | Conteúdo | Próxima |