1. Por que ainda falamos sobre Mainframes?

Chamado por alguns de “dinossauro”, com sua morte anunciada diversas vezes, o mainframe continua cada vez mais presente em antigas e novas empresas. E a revolução provocada pela web, pelas aplicações mobile e pela cloud computing tem tudo a ver com isso.
Grandes empresas ainda mantêm a maior parte de seus processos críticos suportados por sistemas legados que rodam em mainframes. A explicação mais simples é que seria muito caro (ou muito complicado) reconstruir todos os sistemas em plataformas mais modernas. Mas esta é apenas parte da justificativa.
A verdade é que não existem muitas alternativas tecnicamente superiores.
O mainframe tem sido responsável pelos sistemas críticos das maiores organizações do mundo, privadas ou governamentais. Mainframes são equipamentos dedicados à missão crítica dessas organizações e são essenciais para a continuidade das suas operações no dia a dia. Sua enorme capacidade de processamento torna possível o tratamento simultâneo de milhões de transações. Por esse motivo, é mais vantajoso para a maioria dessas empresas melhorar e expandir os sistemas que já existem ao invés de redesenhar, reescrever e retestar milhares e milhares de programas que estão funcionando há décadas.
Mainframes estão no mercado há mais de 50 anos, e ganhando inovações a cada ano. No início de 2015, por exemplo, a IBM® lançou o modelo z13™, com características customizadas para o processamento de grande volume de transações mobile.
“Mas não é mais caro do que as outras soluções?
O custo de hardware, na década de 1990, chegava algumas vezes a 70% dos custos de aquisição, centralizados nas áreas de TI. A arquitetura Cliente/Servidor prometia, pelo menos num primeiro momento, reduzir drasticamente esse custo para as empresas que aderissem à onda do downsizing. Mas uma série de problemas, desconhecidos ou subestimados, começaram a aparecer.
O software e o hardware das plataformas menores não são projetados (ou dimensionados) para a carga monumental de transações e dados das grandes empresas. E aqui estamos falando de todas as transações financeiras Citibank, do Itaú ou do Banco Central do Brasil; ou de todas as declarações de imposto de renda processadas pelo Serpro; ou todas as operações de crédito da Visa…
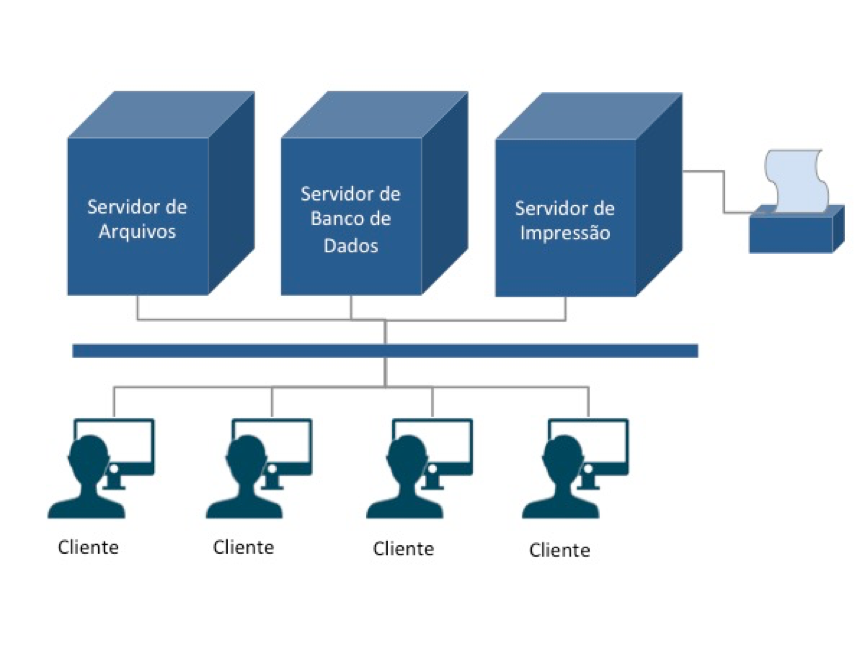
Para contornar esse problema, muitas vezes o que se faz é intensificar a capacidade de distribuição das plataformas mais novas: um servidor para cada serviço ou aplicação. O resultado foi uma enorme ineficiência no uso dos equipamentos.
Estudo recente da International Data Corporation (IDC) mostra que os cerca de 30 milhões de servidores que existem no mundo têm uma utilização média de 15%. O mesmo IDC estima que o excesso de capacidade instalada nesses servidores representa um volume de US$ 140 bilhões de dólares. Algumas estimativas falam em 10% a 15% de uso para servidores de base Intel ou AMD, 15% a 30% para servidores RISC e 80% para mainframes.
As empresas perceberam que mais importante do que o custo de aquisição (total cost of acquisition, ou TCA) era o custo de propriedade (total cost of ownership, ou TCO). Adquirir um servidor Intel® ou RISC era sem dúvida mais barato que adquirir um mainframe. Mas o custo para uma empresa manter dezenas ou centenas de servidores por um período de 3 a 5 anos, considerando gastos com pessoal, energia, refrigeração, suporte, gerenciamento, softwares, aplicativos, upgrades e procedimentos operacionais mostrou que nem sempre a promessa da redução de custos se cumpre.

“Mas é possível virtualizar tudo isso”
O crescimento exponencial da internet nos últimos 10 ou 15 anos popularizou os computadores pessoais, que se tornaram os novos eletrodomésticos de quase todas as casas.
Esse mesmo crescimento, por outro lado, trouxe muitos desafios para os grandes provedores de serviços digitais: era preciso racionalizar a ociosidade de servidores através do balanceamento efetivo e automático de carga. Em outras palavras, um servidor ocioso deveria disponibilizar sua capacidade para outro equipamento que estivesse sobrecarregado. E isso deveria ser feito de forma rápida e automática.
A indústria de TI começou a discutir a necessidade de avanços no conceito de virtualização. Servidores Intel, AMD® e RISC começaram a aparecer com algumas propostas. Grandes empresas, como a VMWare®, surgiram e cresceram apostando na virtualização para racionalizar os custos de seus clientes.
Mas os mainframes já faziam isso desde os anos 1970.
O sistema operacional VM/370™, da IBM, foi o primeiro a implementar o conceito de máquinas virtuais com balanceamento automático de carga. O VM permitia a criação de milhares de máquinas virtuais, cada máquina tinha seus próprios discos virtuais, rodando suas próprias aplicações, em um único equipamento físico. O servidor de banco de dados, por exemplo, era uma dessas máquinas virtuais, fornecendo seus serviços para as demais.
Mais do que isso, se uma das máquinas virtuais sobrecarregasse a CPU ou o sistema de I/O, o próprio VM se encarregava de redistribuir os recursos do equipamento físico de tal forma que nenhuma máquina virtual tivesse sua performance prejudicada.
Já havia, portanto, uma tecnologia funcional, testada, escalável e confiável rodando em mainframes por mais de trinta anos. Essa opção, associada a um novo entendimento das empresas sobre os custos de propriedade (TCO), fez com que o mainframe mantivesse (e até crescesse) na atenção dispensada por institutos de pesquisa, revistas especializadas e mercado consumidor corporativo.

“Mas é uma arquitetura fechada”
Uma das maiores angústias do CIOs quando pensam em suas plataformas é o alto custo envolvido nas manutenções de hardware e licenças de softwares que rodam na plataforma mainframe.
Essa realidade, porém, ficou mais flexível nos últimos anos. Em 2015, por exemplo, a IBM anunciou o projeto LinuxOne que consiste em mainframes equipados exclusivamente com o sistema Linux e diversos softwares livres, como Apache Spark, MariaDB, PostgresSQL e Chef.
Além disso, é possível compartilhar diversos sistemas operacionais diferentes em um mesmo equipamento físico. Uma empresa pode, por exemplo, manter seus sistemas legados rodando embaixo do z/OS®, e transferir toda a sua plataforma Java para rodar numa das máquinas virtuais que esteja carregada com o sistema operacional Linux distribuído por Red Hat, SUSE ou Ubuntu.
“Mesmo assim, por que simplesmente não migram?”
Em meados dos anos 1990, o mercado de TI foi sacudido pela “constatação” de que muitos sistemas corporativos que rodavam em mainframes poderiam parar de funcionar ou produzir resultados imprevisíveis em torno do dia 1 de janeiro de 2000. Isso ficou conhecido como o “bug do milêmio”.
Isso aconteceria porque os antigos sistemas haviam seguido um padrão de armazenamento de datas usando apenas dois dígitos para representar o ano. Por exemplo, 25 de outubro de 1967 era armazenado como 671025. Na virada do milênio, esses sistemas interpretariam a data 01/01/00 como 1º de janeiro de 1900.
Discutiu-se muito nesse momento se não havia chegado finalmente a hora de substituir os grandes e caros mainframes por um conjunto de servidores menores, e migrar todos os sistemas escritos em COBOL, PL/1 ou Natural para linguagens mais modernas e amigáveis.
Cada empresa fez sua conta. E essa conta considerava:
- A compra de novo hardware, que garantisse a mesma confiabilidade
- A compra de novo software básico, que também deveria garantir a mesma confiabilidade
- O treinamento e/ou a contratação de novos profissionais, para atuar na nova plataforma
- A aquisição de pacotes que pudessem substituir todas as funcionalidades dos antigos sistemas; e/ou a especificação, construção e teste de novos sistemas aplicativos, nas novas linguagens
- A migração de todos os dados definitivos e temporários da antiga para a nova plataforma, prevendo um plano de roll-out que garantisse uma transição gradual sem afetar a operação da empresa
- A definição de novos procedimentos e políticas para operação do novo ambiente: backup, manutenção de base de dados, segurança, auditoria, recuperação de desastres etc.
- O treinamento de todos os usuários da corporação nos novos sistemas
A conta ficou cara.
Não foi barato também ajustar milhões de linhas de código para contornar o problema do ano de dois dígitos. Mas ajustar e testar os sistemas legados custaria muito menos dinheiro. E essa foi a solução adotada pela maioria absoluta das empresas usuárias de mainframes.

“É difícil encontrar mão-de-obra”
O bug do milênio serviu como um alerta para um problema que começava a dar sinais naquele momento: a falta de profissionais qualificados nesta plataforma.
No final dos anos 1990, não foi fácil montar equipes para analisar impacto, especificar, alterar, testar e implantar programas em Cobol, PL/1, Natural, Assembler, Mantis, Easytrieve, Rexx ou CSP.
As empresas, muitas vezes, tiveram que recorrer a profissionais que já estavam aposentados ou que já tinham mudado de área. Muitas empresas também precisaram treinar novos profissionais às pressas, uma vez que a virada do ano 2000 não podia ser adiada.
E esse, de fato, é um problema que tende a se agravar. A formação de novos profissionais é significativamente inferior às aposentadorias ou simples mudanças de área.
Além disso, o tempo necessário para formar um profissional sênior em mainframes é maior do que em outras plataformas. Um analista de suporte sênior em mainframe (sênior no sentido de resolver sozinho os desafios que vier a enfrentar) não atinge esse estágio antes dos cinco anos de experiência. E assim mesmo, provavelmente será especialista em um ou dois dos diversos produtos de software que compõem o ambiente operacional de uma instalação mainframe.
Na mesma linha, um analista ou programador experiente em COBOL não é aquele que simplesmente consegue entender que o comando DISPLAY é semelhante ao SYSTEM.OUT.PRINTLN do Java. Especificar e construir programas para a plataforma mainframe exigem paradigmas diferentes. E isso se consegue com treinamento e experiência.
Uma pesquisa realizada em 2012 pela Compuware com 520 CIOs de grandes empresas constatou que 71% estão preocupados com a falta de especialistas em mainframes. Eles temem que a escassez de profissionais prejudique os negócios e coloque a produtividade em risco.
Outro artigo, publicado por Mitzi Hunter, na Enterprise Media System, questiona: por que as empresas foram tão eficientes para resolver o bug do milênio no final dos anos 1990 mas não parecem se organizar para a eminente falta de mão-de-obra em seus sistemas críticos? Ele mesmo sugere como resposta que, enquanto o problema do “ano de dois dígitos” tinham uma data certa para acontecer, a redução do número de profissionais especializados é gradativa e será percebida de forma diluída nos próximos anos.
| Anterior | Conteúdo | Próxima |